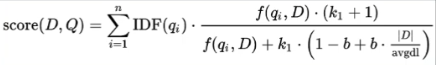01_Ранжирование
Ранжирование - упорядочивание объектов в соответствии с некоторой мерой, т е создание частично упорядоченного множества. Может быть указана зависимость для пар объектов. Следовательно, некоторые пары могут быть не связаны соотношением, т к относятся к разным множествам зависимостей.
Матчинг (соответствие) - процесс сопоставления объектов на основе сравнения и расчета некоторой меры схожести. Подзадача ранжирования.
Learning to rank - класс задач ML с учителем (с частичным привлечением учителя) поиска модели наилучшего приближения и обобщения способа ранжирования. Пример: псевдолейблинг. Небольшое количество данных с разметкой, затем предсказания на огромном объеме данных. Предсказания становятся источником для обучения.
Мера релевантности - степень соответствия между запросом и набором документов.
SKU - идентификатор товарной позиции, идентификатор сущности (не обязательно физический товар).
TP (True Positives) — верно предсказанные положительные случаи
FP (False Positives) — ложноположительные (модель сказала “да”, но это ошибка)
TN (True Negatives) — верно предсказанные отрицательные случаи
FN (False Negatives) — ложноотрицательные (модель сказала “нет”, но это ошибка)
Качество ранжирования
Критерии репрезентативности выборки:
- соответствие структуры выборки структуре реальных данных
- Отсутствие систематического смещения (bias) Данные не должны быть перекошены в сторону одной группы.
- Достаточный объем
- Случайный или контролируемый отбор
Критерии качества ранжирования
- Качество / точность
- Эффективность (скорость предоставления ответа, объем ресурсов)
- Удобство использования
Методология оценки Кранфилда: оценка релевантности моделей на основе фиксированных репрезентативных наборов документов и запросов.
Метрики рассчитываются по топу документов, обозначается metric@k. Например recall@5 это полнота среди 5 документов.
Метрика точность
Из всех объектов, которые модель назвала положительными, какая доля действительно положительная?
Precision = TP / (TP + FP)
Precision = кол-во найденных релевантных документов среди выданных / кол-во выданных
Метрика полнота
Из всех реально положительных объектов сколько мы нашли?
Recall = TP / (TP + FN)
Recall = кол-во найденных положительных релевантных документов среди выданных / кол-во положительных релевантных документов
Fb-мера
Агрегированный критерий качества, b - вес точности в метрике. Способ объединения двух метрик.
Fb = (1 + b^2) precision * recall / (b^2 * precision + recall)
PR-кривая
- сортируем предсказания по убыванию релевантности
- считаем значение точности и полноты в первой паре
- снижаем значение порога, чтобы попало две пары
- повторяем, пока не попали все элементы
Метрика - площадь под PR кривой
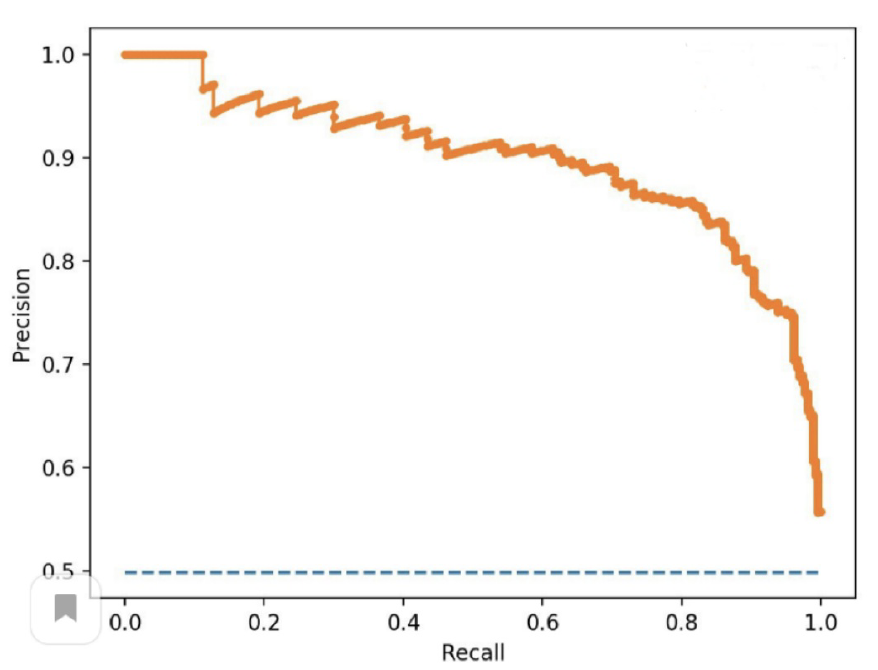
Average Precision
Сколько релевантных объектов сконцентрировано среди самых высоко оцененных.
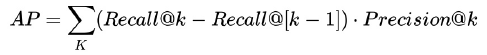
Main avarage precision
MAP = AP / Q
Качество многоуровневого ранжирования
Cumulative gain - сумма рангов
Discounted cumulative gain - сумма, каждый последующий делится на логарифм по основанию 2 от номера позиции. DCG@k
IdealDCG@k считается для случая идеальной выдачи
Normalized DCG = DCG@k/IdealDCG@k
Обучение моделей ранжирования
- Pointwise (поточечный) функция ошибки по конкретному объекту минимизируется
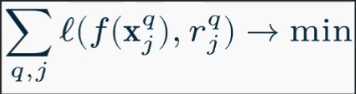
- Pairwise (попарный) функция ошибки по паре объектов минимизируется RankNet
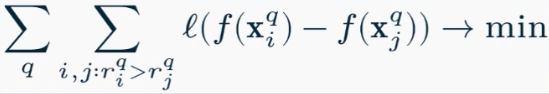
- Listwise (списочный) функция ошибки на всем списке документов ListNet
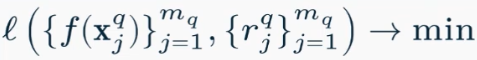
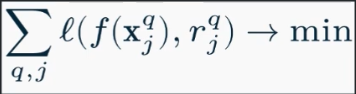
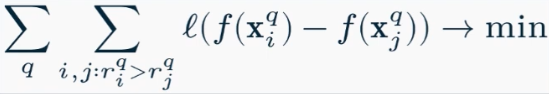
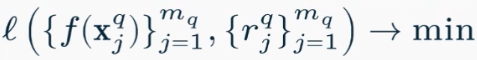
Поточечные методы
BM25: