Python
- FastApi
- SQLAlchemy
- Alembic
- Модули
- Rabbitmq
- Тестирование Playwright
- Начало
- Локаторы
- Actions
- События (Events)
- Аутентификация
- Pytest & Playwright
- Дополнительные возможности
- Ожидание
- Pytest
- Asyncio
- GUI
- GUI QT6
- QT6 + оглавление
- QT6Core
- QT6 настройка окна
- QT6 desiner
- QT6 QLabel, LCD
- QT6 Buttons
- QT6 QLineEdit
- QT6 CheckBox, SpinBox, ComboBox
- QT6 QSlider, QListWidget
- QT6 QTable, QMessageBox, Dialogs
- Пример: notepad
- QT6: База данных
- Авторизация
- Тестирование
- Black hat python
- VK
- Streamlit
- Общее
FastApi
Общие команды
Установка
pip install fastapi uvicornРучной запуск (api - имя файла, app - имя объекта FastApi)
uvicorn api:app --port 8000 --reloadЗапуск uvicorn из python скрипта
Файл main.py
from fastapi import FastAPI
from uvicorn import run
...
app = FastAPI()
...
if __name__ == '__main__':
run(app="main:app", host='0.0.0.0', port=8000, workers=4, log_level='warning')
#run(app="main:app", host='0.0.0.0', port=8000, reload=True)Запросы
curl запросы
curl -X 'GET' 'http://127.0.0.1:8000/todo' -H 'accept: application/json' curl -X 'POST' \
'http://127.0.0.1:8000/todo' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"id": 1,
"item": "First Todo is to finish this book!"
}'Requests
import requests
r = requests.get("http://localhost:8000/hi")
print(r.json())Передача параметров
params = {"who": "Mom"}
r = requests.get("http://localhost:8000/hi", params=params)Httpx
import httpx
r = httpx.get("http://localhost:8000/hi")
print(r.json())Автоматическая документация
Swagger
http://ip:port/docsRedoc
http://ip:port/redocШаблоны Jinja
Поддерживает шаблоны Jinja при выводе данных (вплоть до циклов).
Маршрутизация
Параметризация запросов
Передача параметров в запросе
@app.get("/hi/{who}")
def greet(who):
return f"Hello? {who}?"Передача параметров в параметре запроса
@app.get("/hi")
def greet(who):
return f"Hello? {who}?"Запрос типа localhost:8000/hi?who=Mom
Параметры передавать можно в параметрах запроса, в заголовках, в теле запроса, кукисах, ...
Добавление маршрутов
Основной файл:
from fastapi import FastAPI
from todo import todo_router
app = FastAPI()
@app.get("/")
async def welcome() -> dict:
return {
"message": "Hello World"
}
app.include_router(todo_router)Файл дополнительных маршрутов
from fastapi import APIRouter
todo_router = APIRouter()
todo_list = []
@todo_router.post("/todo")
async def add_todo(todo: dict) -> dict:
todo_list.append(todo)
return {"message": "Todo added successfully"}
@todo_router.get("/todo")
async def retrieve_todos() -> dict:
return {"todos": todo_list}Автоматическое добавление маршрутов в основной файл app из файлов в директории data/plugins имеющих шаблон имени объекта APIRouter modulename_router
fpath = os.path.join('data', 'plugins')
flist = os.listdir(fpath)
sys.path.insert(0, fpath)
for fname in flist:
if fname not in ['__pycache__', '__init__.py']:
m = os.path.splitext(fname)[0]
impmod = importlib.import_module(m)
router_name = f'{m}_router'
if router_name in dir(impmod):
router_mod = getattr(impmod, router_name)
app.include_router(router_mod)Возвращаемые данные
По умолчанию возвращается JSON, добавляется заголовок Status Code и Content-type: application/json.
При помощи response_model можно фильтровать отдаваемые данные. Т е можно в отдаваемой модели указать неполный набор.
from typing import List
class TodoItem(BaseModel):
item: str
class TodoItems(BaseModel):
todos: List[TodoItem]@todo_router.get("/todo", response_model=TodoItems)
async def retrieve_todo() -> dict:
return {
"todos": todo_list
}У содержащихся в списке словарей будет оставлен только item
Исключения
Класс HTTPException принимает три аргумента:
- status_code: Код состояния, который будет возвращен для этого сбоя
- detail: Сопроводительное сообщение для отправки клиенту
- headers: Необязательный параметр для ответов, требующих заголовков
from fastapi import APIRouter, Path, HTTPException, status
@todo_router.get("/todo/{todo_id}")
async def get_single_todo(todo_id: int = Path(..., title="The ID of the todo to retrieve.")) -> dict:
for todo in todo_list:
if todo.id == todo_id:
return { "todo": todo }
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="Todo with supplied ID doesn't exist",
)Можно переопределить код успешного возврата в декораторе
@todo_router.post("/todo", status_code=201)
async def add_todo(todo: Todo) -> dict:
todo_list.append(todo)
return { "message": "Todo added successfully." }Pydantic
class Item(BaseModel):
item: str
status: str
class Todo(BaseModel):
id: int
item: Item
Jinja2
{# This is a great API book! #} комментарии
| Способ | Описание |
| {% include %} | Позволяет включить содержимое другого шаблона целиком.
|
| {% extends %} + {% block %} |
Наследование шаблонов и переопределение блоков. Базовый шаблон Дочерний шаблон
|
{{ variable | filter_name(*args) }}| Название | Описание |
| default(strdefault) |
Замена вывода переданного значения, если оно оказывается None |
| escape | Отображение необработанного вывода HTML |
| striptags | Удаление HTML тетов перед отправкой |
|
int float |
Преобразование типов перед ответом |
| join(whitespace) | Объединение элементов списка в строку
|
| length | Длина переданного объекта
|
{% if user %}
Hello, {{ user.name }}!
{% else %}
Hello, Unknown!
{% endif %}{% for comment in comments %}
<b>{{ comment }}</b>
{% endfor %}| Переменная | Описание |
| loop.index | Текущее значение итерации (1 - первая итерация) |
| loop.index0 | Текущее значение итерации (0 - первая итерация) |
| loop.revindex loop.revindex0 | Кол-во оставшихся итераций |
| loop.first | True если первая итерация |
| loop.last | |
| loop.length | |
| loop.pervitem loop.nextitem | Значение предыдущей/следующей итерации (пусто если не существует) |
Авторизация и аутентификация
Ссылки:
Подготовка проекта
python -m venv --system-site-packages env
python -m pip install fastapi uvicorn
SQLAlchemy
Sqlalchemy
pip install sqlalchemypip install psycopg2pip install psycopg2-binarypip install pymysqlfrom sqlalchemy import create_engine
engine = create_engine('postgresql+psycopg2://username:password@localhost:5432/mydb')
engine = create_engine('mysql+pymysql://cookiem:chip@mysql01.com/cookies', pool_recycle=3600)
engine = create_engine('sqlite:///cookies.db')
engine2 = create_engine('sqlite:///:memory:')| echo | булево. Лог запросов. По-умолчанию False. |
| encoding | строка. По-умолчанию utf-8 |
| isolation_level | уровень изоляции |
| pool_recycle | число секунд для переподключения, желательно выставлять 3600. При работе с mysql соединение может быть активным до 4 часов. |
Создание engine не создает фактического соединения с БД.
connection = engine.connect()Сырой запрос:
result = connection.execute("select * from orders").fetchall()- Может получать информацию о существующих сейчас сущностях в БД
- Может хранить шаблоны именования индексов и ограничений (constraint). Т е перед началом проекта добавляется настройка именования, затем при создании/удалении все ок. Это словарь ограничение:шаблон
| Ограничение или индекс | Описание |
| ix | обычный индекс |
| uq | уникальный индекс |
| ck | ограничение проверки |
| fk | foreign-ключ |
| pk | primary-ключ |
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(all_column_names)s',
'fk': ('fk__%(table_name)s__%(all_column_names)s' '%(referred_table_name)s'),
'pk': 'pk__%(table_name)s'
}
metadata_obj = MetaData(naming_convention=convention)- Должен быть инициализирован до обращения к нему в таблицах
- Изначально пустой объект, можно или вручную занести данные, или получить из базы.
- Получение информации об одной таблице по имени
- Нельзя получить одновременно две таблицы. Либо одна, либо вся база
- Нельзя (и одна таблица, и база) получить ограничения (CONSTRAINT), комментарии, триггеры, значения по умолчанию. Но можно вручную добавить данные. Но похоже проще импортировать описание.
from sqlalchemy import ForeignKeyConstraint
album.append_constraint(ForeignKeyConstraint(['ArtistId'], ['artist.ArtistId']))-
- при получении базы, имена таблиц с большой и маленькой буквы. Т е удваивается количество объектов.
engine = create_engine(...)
metadata = MetaData()
cookie_tbl = Table('cookies', metadata, autoload_with=engine)
s = select(cookie_tbl)
with engine.connect() as conn:
m = conn.execute(s)
print(m.keys())- Получение информации обо всей базе
from sqlalchemy import create_engine, MetaData
engine = create_engine(...)
metadata = MetaData()
metadata.reflect(bind=engine)
for table in metadata.sorted_tables:
print(table.name)
#Потом получить объект таблицы:
mytable = metadata.tables['mytable']- Получение информации обо всей базе через ORM + Automap
from sqlalchemy.ext.automap import automap_base
from sqlalchemy import create_engine
Base = automap_base()
engine = create_engine('sqlite:///Chinook_Sqlite.sqlite')
Base.prepare(engine, reflect=True)
# данные о классах загружены.
#Например для получения списка классов:
Base.classes.keys()
Artist = Base.classes.Artist # создание классов
#Внешние связи - в свойстве <related_object>_collection
artist = session.query(Artist).first()
for album in artist.album_collection:
print('{} - {}'.format(artist.Name, album.Title))Dialect: Скрывает детали реализации в конкретной базе
Core: SQL в чистом виде
ORM: абстракции
ins = cookies.insert().values(
cookie_name="chocolate chip",
cookie_recipe_url="http://some.aweso.me/cookie/recipe.html",
cookie_sku="CC01",
quantity="12",
unit_cost="0.50"
)
result = connection.execute(ins)
print(result.inserted_primary_key)from sqlalchemy import insert
ins = insert(cookies).values(
cookie_name="chocolate chip",
cookie_recipe_url="http://some.aweso.me/cookie/recipe.html",
cookie_sku="CC01",
quantity="12",
unit_cost="0.50"
)ins = cookies.insert()
result = connection.execute(
ins,
cookie_name='dark chocolate chip',
cookie_recipe_url='http://some.aweso.me/cookie/recipe_dark.html',
cookie_sku='CC02',
quantity='1',
unit_cost='0.75'
)
result.inserted_primary_keyinventory_list = [
{
'cookie_name': 'peanut butter',
'cookie_recipe_url': 'http://some.aweso.me/cookie/peanut.html',
'cookie_sku': 'PB01',
'quantity': '24',
'unit_cost': '0.25'
},
{
'cookie_name': 'oatmeal raisin',
'cookie_recipe_url': 'http://some.okay.me/cookie/raisin.html',
'cookie_sku': 'EWW01',
'quantity': '100',
'unit_cost': '1.00'
}
]
result = connection.execute(ins, inventory_list)from sqlalchemy.sql import select
s = select([cookies])
rp = connection.execute(s)
results = rp.fetchall()s = cookies.select()
rp = connection.execute(s)
results = rp.fetchall()s = cookies.select()
rp = connection.execute(s)
for record in rp:
print(record.cookie_name)s = select([cookies.c.cookie_name, cookies.c.quantity])s = select([cookies.c.cookie_name, cookies.c.quantity])s = s.order_by(cookies.c.quantity)s = s.order_by(desc(cookies.c.quantity))rp = connection.execute(s)s = select([cookies.c.cookie_name, cookies.c.quantity])
s = s.order_by(cookies.c.quantity)
s = s.limit(2)
rp = connection.execute(s)from sqlalchemy.sql import func
s = select([func.sum(cookies.c.quantity)])
rp = connection.execute(s)
print(rp.scalar())s = select([func.count(cookies.c.cookie_name)])
rp = connection.execute(s)
record = rp.first()
print(record.keys()) # ключи могут быть разные.
print(record.count_1) s = select([func.count(cookies.c.cookie_name).label('inventory_count')])
rp = connection.execute(s)
record = rp.first()
print(record.keys())
print(record.inventory_count)s = select([cookies]).where(cookies.c.cookie_name == 'chocolate chip')
rp = connection.execute(s)- between(cleft, cright) Значение столбца между cleft и cright
- concat(column_two) Объединение column и column_two
- distinct() Находит только уникальные значения в столбце
- in_([list]) Только если значения столбца в списке
- is_(None) Проверка на пустые значения
- contains(string) Значение столбца содержит строку
- endswith(string) Оканчивается строкой, зависит от больших букв
- like(string) зависит от больших букв
- startswith(string) зависит от больших букв
- ilike(string) не зависит от больших букв
- Есть отрицательные модификаторы not<method>, исключение - метод isnot()
s = select([cookies]).where(cookies.c.cookie_name.like('%chocolate%'))
rp = connection.execute(s)
for record in rp.fetchall():
print(record.cookie_name)s = select([cookies.c.cookie_name, 'SKU-' + cookies.c.cookie_sku]) - добавит строку 'SKU-'from sqlalchemy import cast
s = select([cookies.c.cookie_name,
cast((cookies.c.quantity * cookies.c.unit_cost),
Numeric(12,2)).label('inv_cost')])
for row in connection.execute(s):
print('{} - {}'.format(row.cookie_name, row.inv_cost))from sqlalchemy import and_, or_, not_
s = select([cookies]).where(
and_(
cookies.c.quantity > 23,
cookies.c.unit_cost < 0.40
)
)first_row = results[0]
first_row[1]
first_row.cookie_name
first_row[cookies.c.cookie_name]- first() - Первая запись и закрытие соединения
- fetchone() - Одна запись и оставляет открытый курсор для последующих запросов
- scalar() - Одно значение если запрос возвращает одно значение в одной строке
- rp.keys() - список столбцов
from sqlalchemy import update
u = update(cookies).where(cookies.c.cookie_name == "chocolate chip")
u = u.values(quantity=(cookies.c.quantity + 120))
result = connection.execute(u)from sqlalchemy import delete
u = delete(cookies).where(cookies.c.cookie_name == "dark chocolate chip")
result = connection.execute(u)columns = [orders.c.order_id, users.c.username, users.c.phone,
cookies.c.cookie_name, line_items.c.quantity,
line_items.c.extended_cost]
cookiemon_orders = select(columns)
cookiemon_orders = cookiemon_orders.select_from(orders.join(users).join(
line_items).join(cookies)).where(users.c.username ==
'cookiemon')
result = connection.execute(cookiemon_orders).fetchall()columns = [users.c.username, func.count(orders.c.order_id)]
all_orders = select(columns)
all_orders = all_orders.select_from(users.outerjoin(orders))
all_orders = all_orders.group_by(users.c.username)
result = connection.execute(all_orders).fetchall()columns = [users.c.username, func.count(orders.c.order_id)]
all_orders = select(columns)
all_orders = all_orders.select_from(users.outerjoin(orders))
all_orders = all_orders.group_by(users.c.username)
result = connection.execute(all_orders).fetchall()def get_orders_by_customer(cust_name, shipped=None, details=False):
columns = [orders.c.order_id, users.c.username, users.c.phone]
joins = users.join(orders)
if details:
columns.extend([cookies.c.cookie_name, line_items.c.quantity,
line_items.c.extended_cost])
joins = joins.join(line_items).join(cookies)
cust_orders = select(columns)
cust_orders = cust_orders.select_from(joins)
cust_orders = cust_orders.where(users.c.username == cust_name)
if shipped is not None:
cust_orders = cust_orders.where(orders.c.shipped == shipped)
result = connection.execute(cust_orders).fetchall()
return result
get_orders_by_customer('cakeeater')
get_orders_by_customer('cakeeater', details=True)
get_orders_by_customer('cakeeater', shipped=True)
get_orders_by_customer('cakeeater', shipped=False)
get_orders_by_customer('cakeeater', shipped=False, details=True) ORM режим
Таблица это класс с требованиями:
- Потомок объекта, возвращаемого функцией declarative_base
- Включает __tablename__ с именем таблицы
- Включает 1+ атрибутов, являющихся объектом Column
- При определении не включает имя столбца в конструкторе Column, имя столбца = имя атрибута
- 1+ атрибутов определяют первичный ключ
- __table_args__ свойства таблицы (ограничения,...)
from sqlalchemy import Table, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Cookie(Base):
__tablename__ = 'cookies'
__table_args__ = (CheckConstraint('quantity >= 0', name='quantity_positive'),)
cookie_id = Column(Integer(), primary_key=True)
cookie_name = Column(String(50), index=True)
quantity = Column(Integer())Создание таблиц
from sqlalchemy import create_engine
from dataclasses import Base
engine = create_engine(...)
Base.metadata.create_all(engine)Ограничения
__table_args__ = (ForeignKeyConstraint(['id'], ['other_table.id']), CheckConstraint(unit_cost >= 0.00', name='unit_cost_positive'))
Внешние связи
- Определяется столбец с ForeignKey
- Определяется дополнительный атрибут с relationship и необязательным backref
- При определении backref, relationship будет определен в указанном классе с указанным именем.
Один к одному:
cookie = relationship("Cookie", uselist=False)Один ко многим:
user = relationship("User", backref=backref('orders'))На себя (дерево) - неоднозначное решение.
class Employee(Base):
__tablename__ = 'employees'
id = Column(Integer(), primary_key=True)
manager_id = Column(Integer(), ForeignKey('employees.id'))
name = Column(String(255), nullable=False)
manager = relationship("Employee", backref=backref('reports'), remote_side=[id])Сессии
В ORM режиме, сессия упаковывает
- соединение с БД через engine и предоставляет словарь объектов, загруженных через сессию или ассоциированных с сессией
- транзакции, которые открыты до коммита сессии
Это похожая на хэш-систему, состоящую из списка объектов, таблиц и ключей. Сессия создается через sessionmaker, один раз. Соединяется с базой в момент необходимости
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine('sqlite:///:memory:')
Session = sessionmaker(bind=engine)
session = Session()Состояния объекта в сессии:
| Transient | Объект не в сессии и не в БД |
| Pending | Объект добавлен в сессию add(), но не flush или commit |
| Persistent | Объект в сессии имеет связанную запись в БД |
| Detached | Объект больше не в сессии, но в БД есть соответствующая запись |
| Modified | Объект изменен |
Просмотр состояния:
from sqlalchemy import inspect
insp = inspect(cc_cookie)Отключение объекта от сессии:
session.expunge(cc_cookie)Просмотр списка атрибутов и выяснение, что было модифицировано
for attr, attr_state in insp.attrs.items():
if attr_state.history.has_changes():
print('{}: {}'.format(attr, attr_state.value))
print('History: {}\n'.format(attr_state.history))Добавление данных
Создаем объект класса, добавляем в сессию и коммитим. Множественное добавление данных:
dcc = Cookie(...)
mcc = Cookie(...)
session.add(dcc)
session.add(mcc)
session.flush()flush: не выполняет коммит и не завершает транзакцию, но получает id. Потом нужно в пределах сессии сделать commit. Commit в пределах чужой сессии не влияет. Дальше можно использовать объект.
Если дальше не нужно выполнять операции с объектами:
session.bulk_save_objects([dcc,mcc])
session.commit()Получение данных
| all() | все |
| first() | возвращает одну запись если она единственная и закрывает соединение |
| one() | возвращает одну запись и оставляет соединение. Аккуратно! |
| scalar() | возвращает одно значение если результат запроса одна строка с одним столбцом |
cookies = session.query(Cookie).all()
print(cookies)Если использовать через итератор, то без all:
for cookie in session.query(Cookie):
print(cookie)Получение определенных столбцов:
cookies = session.query(Cookie.cookie_id).all()Сортировка:
session.query(Cookie).order_by(Cookie.quantity).all()
.order_by(desc(Cookie.quantity))Ограничения через срезы или .limit(2)
Встроенные функции:
from sqlalchemy import func
inv_count = session.query(func.sum(Cookie.quantity)).scalar()
print(inv_count)
rec_count = session.query(func.count(Cookie.cookie_name)).first()Метки: можно добавить для дальнейшего обращения
rec_count = session.query(func.count(Cookie.cookie_name).label('inventory_count')).first()
print(rec_count.inventory_count)Фильтрация
record = session.query(Cookie).filter(cookie_name=='chocolate chip').first()
record = session.query(Cookie).filter_by(cookie_name='chocolate chip').first()
query = session.query(Cookie).filter(Cookie.cookie_name.like('%chocolate%'))
query = session.query(Cookie).filter(Cookie.quantity > 23, Cookie.unit_cost < 0.40)Изменение строк при выводе
results = session.query(Cookie.cookie_name, 'SKU-' + Cookie.cookie_sku).all()
query = session.query(Cookie.cookie_name,
cast((Cookie.quantity * Cookie.unit_cost),
Numeric(12,2)).label('inv_cost'))Join:
query = session.query(Order.order_id, User.username)
results = query.join(User).all()
query = session.query(User.username, func.count(Order.order_id))
query = query.outerjoin(Order).group_by(User.username)Group:
query = session.query(User.username, func.count(Order.order_id))
query = query.outerjoin(Order).group_by(User.username)Сырые запросы
from sqlalchemy import text
query = session.query(User).filter(text("username='cookiemon'"))Обновление данных
Через объект
query = session.query(Cookie)
cc_cookie = query.filter(Cookie.cookie_name == "chocolate chip").first()
cc_cookie.quantity = cc_cookie.quantity + 120
session.commit()Через метод update
query = session.query(Cookie)
query = query.filter(Cookie.cookie_name == "chocolate chip")
query.update({Cookie.quantity: Cookie.quantity - 20})Удаление
session.delete(dcc_cookie)
session.commit()Исключения
from sqlalchemy.orm.exc import MultipleResultsFound
try:
results = session.query(Cookie).one()
except MultipleResultsFound as error:
print('We found too many cookies... is that even possible?')Транзакции
В ORM транзакция создается автоматически до очередного коммита.
session.add(order)
try:
session.commit()
except IntegrityError as error:
session.rollback() Пример структурирования
db.py
from datetime import datetime
from sqlalchemy import (MetaData, Table, Column, Integer, Numeric, String,
DateTime, ForeignKey, Boolean, create_engine)
class DataAccessLayer:
connection = None
engine = None
conn_string = None
metadata = MetaData()
cookies = Table('cookies',
metadata,
Column('cookie_id', Integer(), primary_key=True),
Column('cookie_name', String(50), index=True),
Column('cookie_recipe_url', String(255)),
Column('cookie_sku', String(55)),
Column('quantity', Integer()),
Column('unit_cost', Numeric(12, 2))
)
def db_init(self, conn_string):
self.engine = create_engine(conn_string or self.conn_string)
self.metadata.create_all(self.engine)
self.connection = self.engine.connect()
dal = DataAccessLayer()app.py
from db import dal
from sqlalchemy.sql import select
def get_orders_by_customer(cust_name, shipped=None, details=False):
columns = [dal.orders.c.order_id, dal.users.c.username, dal.users.c.phone]
joins = dal.users.join(dal.orders)
if details:
columns.extend([dal.cookies.c.cookie_name,
dal.line_items.c.quantity,
dal.line_items.c.extended_cost])
joins = joins.join(dal.line_items).join(dal.cookies)
cust_orders = select(columns)
cust_orders = cust_orders.select_from(joins).where(
dal.users.c.username == cust_name)
if shipped is not None:
cust_orders = cust_orders.where(dal.orders.c.shipped == shipped)
return dal.connection.execute(cust_orders).fetchall()test.py
import unittest
class TestApp(unittest.TestCase):
@classmethod
def setUpClass(cls):
dal.db_init('sqlite:///:memory:')
def test_one(self):
res = get_orders_by_customer('', False)
self.assert_equal(res, [])Core режим
Сначала необходимо определить, как данные хранятся в таблице. Варианты определения:
- Объект Table
- Декларативный класс
- Получение структуры из базы данных
Сопоставление типов
| SQLAlchemy | Python | SQL |
| BigInteger | int | BIGINT |
| Boolean | bool | BOOLEAN or SMALLINT |
| Date | datetime.date | DATE (SQLite: STRING) |
| DateTime | datetime.datetime | DATETIME (SQLite: STRING) |
| Time | datetime.time | DATETIME |
| Enum | str | ENUM or VARCHAR |
| Float | float or Decimal | FLOAT or REAL |
| Integer | int | INTEGER |
| Interval | datetime.timedelta | INTERVAL or DATE from epoch |
| LargeBinary | byte | BLOB or BYTEA |
| Numeric | decimal.Decimal | NUMERIC or DECIMAL |
| Unicode | unicode | UNICODE or VARCHAR |
| Text | str | CLOB or TEXT |
Metadata
Каталог объектов Table с опциональной информацией о engine и соединении.
from sqlalchemy import MetaData
metadata = MetaData()Создание таблицы
metadata.create_all(engine)Метод ...create_all не пересоздает таблицы.
Объект таблицы состоит из названия, переменной метаданных и столбцов.
from sqlalchemy import Table, Column, Integer, Numeric, String, ForeignKey
from datetime import datetime
from sqlalchemy import DateTime
cookies = Table('cookies', metadata,
Column('cookie_id', Integer(), primary_key=True),
Column('cookie_name', String(50), index=True),
Column('cookie_recipe_url', String(255)),
Column('cookie_sku', String(55)),
Column('quantity', Integer()),
Column('unit_cost', Numeric(12, 2))
)
users = Table('users', metadata,
Column('user_id', Integer(), primary_key=True),
Column('username', String(15), nullable=False, unique=True),
Column('email_address', String(255), nullable=False),
Column('phone', String(20), nullable=False),
Column('password', String(25), nullable=False),
Column('created_on', DateTime(), default=datetime.now),
Column('updated_on', DateTime(), default=datetime.now, onupdate=datetime.now)
)Класс Column
- название столбца
- тип данных
- в String обязательно указывать длину
- Numeric(11,2) означает 11
- доп. параметры
- тип данных
primary_key=True
index=True
nullable=False
unique=True
default=datetime.now
onupdate=datetime.nowКлючи, ограничения и индексы
Могут быть определены в конструкторе столбца (primary_key=True) или позже в конструкторе таблицы.
from sqlalchemy import PrimaryKeyConstraint, UniqueConstraint, CheckConstraint
users = Table(...
PrimaryKeyConstraint('user_id', name='user_pk'),
UniqueConstraint('username', name='uix_username'),
CheckConstraint('unit_cost >= 0.00', name='unit_cost_positive'),
...)Множественные ключи перечисляются через запятую.
from sqlalchemy import Index
Index('ix_cookies_cookie_name', 'cookie_name')
Index('ix_test', mytable.c.cookie_sku, mytable.c.cookie_name)Внешние связи
from sqlalchemy import ForeignKey
orders = Table('orders', metadata,
Column('order_id', Integer(), primary_key=True),
Column('user_id', ForeignKey('users.user_id')),
Column('shipped', Boolean(), default=False)
)
line_items = Table('line_items', metadata,
Column('line_items_id', Integer(), primary_key=True),
Column('order_id', ForeignKey('orders.order_id')),
Column('cookie_id', ForeignKey('cookies.cookie_id')),
Column('quantity', Integer()),
Column('extended_cost', Numeric(12, 2))
)Связь для поля order_id:
Column('user_id', ForeignKey('users.user_id'))
#При желании - ограничение
ForeignKeyConstraint(['order_id'], ['orders.order_id'])Добавление данных
from sqlalchemy import insert
перем = таблица.insert().values()Лучше (?) вариант
from sqlalchemy import insert
перем = insert(таблица).values()Строковое представление запроса
str(перем)Компиляция запроса
перем.compile()перем.compile().paramsПримеры
with engine.connect() as connection:
metadata = ...
cookies = Table...
ins = insert(cookies).values(...)
res = connection.execute(ins)
#res.inserted_primary_key - какой в будущем будет ключ (сейчас фактически в БД нет данных)
connection.commit()ins = cookies.insert()
inventory_list = [
{
'cookie_name': 'peanut butter',
'cookie_recipe_url': 'http://some.aweso.me/cookie/peanut.html',
},
{
'cookie_name': 'oatmeal raisin',
'cookie_recipe_url': 'http://some.okay.me/cookie/raisin.html',
}
]
result = connection.execute(ins, inventory_list)from sqlalchemy import create_engine
from sqlalchemy import MetaData
from sqlalchemy import Table, Column, Integer, Numeric, String, ForeignKey
metadata = MetaData()
cookies = Table('cookies', metadata,
Column('cookie_id', Integer(), primary_key=True),
Column('cookie_name', String(50), index=True),
Column('cookie_recipe_url', String(255))
)
engine = create_engine('sqlite:///:memory:')
connection = engine.connect()
metadata.create_all(engine)
from sqlalchemy import insert
ins = cookies.insert().values(
cookie_name="chocolate chip",
cookie_recipe_url="http://some.aweso.me/cookie/recipe.html"
)
print(str(ins))Получение данных
from sqlalchemy.sql import select
s = select(cookies)
rp = connection.execute(s)Список столбцов
rp.keys()Получение результата
results = rp.fetchall()| fetchall() | Все записи |
| first() | Возвращает одну запись если она единственная и закрывает соединение |
| fetchone() | Возвращает одну запись и оставляет соединение. Аккуратно! |
| scalar() | Возвращает одно значение если результат запроса одна строка с одним столбцом |
Доступ возможен по:
| first_row = results[0] | по индексу результата |
| first_row[1] | по номеру столбца в результате |
| first_row.cookie_name | по имени столбца |
| first_row[cookies.c.cookie_name] | через объект таблицы |
Сортировка
s = select(cookies.c.cookie_name, cookies.c.quantity)
s = s.order_by(cookies.c.quantity)
s = s.order_by(desc(cookies.c.quantity))Ограничения количества
s = s.limit(2)Встроенные функции
from sqlalchemy.sql import func
s = select([func.sum(cookies.c.quantity)])
rp = connection.execute(s)
print(rp.scalar())Фильтрация
s = select([cookies]).where(cookies.c.cookie_name == 'chocolate chip')| Оператор | Описание |
| == | Точное равенство |
| like('%chocolate%') | Вхождение элемента (регистрозависимый) |
| ilike(string) | Вхождение элемента |
| between(cleft, cright) | Элемент между значениями |
| concat(column_two) | Объединение столбцов |
| distinct() | Только уникальные значения столбца |
| in_([list]) | Значения столбца в списке |
| is_(None) | Значение в столбце None |
| contains(string) | Содержит в себе строку (регистрозависимый) |
| endswith(string) | Заканчивается строкой (регистрозависимый) |
| startswith(string) | Начинается строкой (регистрозависимый) |
| notin_() | Отрицание |
| isnot() | Исключение |
Внутри where можно использовать and_, or_, not_
from sqlalchemy import and_, or_, not_
s = select([cookies]).where(
and_(
cookies.c.quantity > 23,
cookies.c.unit_cost < 0.40
)
)Join
columns = [orders.c.order_id, users.c.username, users.c.phone,
cookies.c.cookie_name, line_items.c.quantity, line_items.c.extended_cost]
cookiemon_orders = select(*columns)
cookiemon_orders = cookiemon_orders.select_from(orders.join(users).join(line_items).join(cookies)).where(users.c.username == 'cookiemon')
result = connection.execute(cookiemon_orders).fetchall()
for row in result:
print(row)Для outerjoin: join -> outerjoin
Алиасы
manager = employee_table.alias('mgr')Grouping:
columns = [users.c.username, func.count(orders.c.order_id)]
all_orders = select(columns)
all_orders = all_orders.select_from(users.outerjoin(orders))
all_orders = all_orders.group_by(users.c.username)Обновление данных:
from sqlalchemy import update
u = update(cookies).where(cookies.c.cookie_name == "chocolate chip")
u = u.values(quantity=(cookies.c.quantity + 120))
result = connection.execute(u)Удаление данных:
from sqlalchemy import delete
u = delete(cookies).where(cookies.c.cookie_name == "dark chocolate chip")
result = connection.execute(u)Сырые запросы (raw)
result = connection.execute("select * from orders").fetchall()Обработка исключений
AttributeError - ошибка набора данных
IntegrityError - ошибка ограничений
Стандартная обработка подходит если исполняется один независимый запрос.
try:
result = connection.execute(ins)
except IntegrityError as error:
print(error.orig.message, error.params)В случае нескольких взаимозависимых запросов необходимо использовать транзакции.
transaction = connection.begin()
try:
...
transaction.commit()
except IntegrityError as error:
transaction.rollback()Пример:
transaction = connection.begin()
cookies_to_ship = connection.execute(s).fetchall()
try:
for cookie in cookies_to_ship:
u = update(cookies).where(cookies.c.cookie_id == cookie.cookie_id)
u = u.values(quantity = cookies.c.quantity-cookie.quantity)
result = connection.execute(u)
u = update(orders).where(orders.c.order_id == order_id)
u = u.values(shipped=True)
result = connection.execute(u)
print("Shipped order ID: {}".format(order_id))
transaction.commit()
except IntegrityError as error:
transaction.rollback()
Пример проекта
Структура проекта
| Директория / файл | Описание |
| alembic/ |
Настройки alembic |
| conf/ | Настройки окружений. |
| conf/settings |
Файлы основных настроек. |
| db/ |
Описание структуры базы данных. initializer.py - Инициализация базы данных, метаданных |
| db/tablesdefinition |
Файлы описания структур таблиц и методов взаимодействия с данными. |
| docker/ | Настройки контейнера |
| docker/data | Данные БД |
| docker/docker-entrypoint-initdb.d |
Скрипты инициализации БД main.sql - Файл скрипта иницализации |
| docker/docker-compose.yml | Compose файл |
| src/ | Дополнительные модули |
| main.py | Точка входа |
| error.log |
Файл лога. |
Предварительная настройка
Для работы примера необходимо установить docker.
Клонировать проекта с репозитория
git clone https://gitverse.ru/bobrobot/alembictemplate.gitПерейти в директорию проекта, создать виртуальное окружение и активировать
cd alembictemplate
python3 -m venv env
source env/bin/activateУстановить дополнительные модули
pip install -r requirements.txtПерейти в директорию docker и в файле docker-compose.yml настроить пути, имя БД, логин и пароль к новой базе данных.
services:
postgres:
image: postgres:latest
environment:
POSTGRES_DB: "learnsqlalchemy"
POSTGRES_USER: "learner"
POSTGRES_PASSWORD: "StrongPassword123"
PGDATA: "/home/sergey/projects/alembictemplate/docker/data/pgdata"
volumes:
- .:/docker-entrypoint-initdb.d
- mydata:/home/sergey/projects/alembictemplate/docker/data
ports:
- "5430:5432"
volumes:
mydata:В файле docker-entrypoint-initdb.d/main.sql изменить имя БД, логин и пароль.
CREATE DATABASE learnsqlalchemy;
CREATE USER learner WITH PASSWORD 'StrongPassword123';
ALTER ROLE learner WITH PASSWORD 'StrongPassword123';
GRANT ALL PRIVILEGES ON DATABASE learnsqlalchemy to learner;В директории docker запустить контейнер БД в фоновом режиме.
docker compose up -dДля остановки контейнера:
docker compose stopСейчас, запустив контейнер, при помощи консольного клиента psql можно проверить соединение с базой данных для пользователя.
psql -d learnsqlalchemy -U learner -W -h 127.0.0.1 -p 5430Для работы с настройками в формате json используется библиотека src/libsettings.py Описание библиотеки Создать папку src, скопировать из проекта библиотеку libsettings.py
Настройки системы
Файлы основных настроек расположены в conf/settings/ Файл base.py
'''Loading settings to project'''
import os
from src.libsettings import Jsettings
settingspath = os.path.join('conf', 'settings', 'settings.json')
schemapath = os.path.join('conf', 'settings', 'schema.json')
# dev settings
mysettings = Jsettings(settingsfname= settingspath,
schemafname=schemapath)
mysettings.load_settings()Файл schema.json
{
"type": "object",
"properties": {
"db_username": {"type": "string"},
"db_password": {"type": "string"},
"db_host": {"type": "string"},
"db_port": {"type": "string"},
"db_name": {"type": "string"}
},
"required": ["db_username", "db_password", "db_host",
"db_port", "db_name"]
}Файл settings.json
{
"db_username": "learner",
"db_password": "StrongPassword123",
"db_host": "127.0.0.1",
"db_port": "5430",
"db_name": "learnsqlalchemy"
}Файл base.py проверяет схему и создает объект настроек mysettings из файла settings.json. Для получения объекта настроек нужно импортировать объект mysettings в нужном модуле. В данный момент присутствуют настройки базы данных с префиксом db_*
Если такая усложненная система управления настройками покажется излишней, возможно использовать экспорт настроек напрямую из файла.
Инициализация базы данных
Создаем папку db, в ней создаем файл initializer.py
'''Db classes and initialization'''
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base
from conf.settings.base import mysettings
#load engine settings
engine = create_engine(
"postgresql+psycopg2://{db_username}:{db_password}@{db_host}:{db_port}/{db_name}".format(
db_username=mysettings.db_username,
db_password=mysettings.db_password,
db_host=mysettings.db_host,
db_port=mysettings.db_port,
db_name=mysettings.db_name
),
echo=True)
Base = declarative_base()Здесь только создается engine для подключения к БД и класс Base. При настройке структуры таблиц данный файл будет обновлен, сейчас нужен только класс Base.
Настройка системы версионирования базы данных alembic
Инициализируем alembic в корне проекта.
alembic init alembicВ корне проекта будет создан файл alembic.ini, будет создана папка alembic с файлами инициализации. В большинстве инструкций параметры подключения задаются в файле alembic.ini однако, для доступа к настройкам из единой точки будет изпользоваться способ установки параметров в файле env.py Поэтому в файле alembic.ini переменная sqlalchemy.url должна быть закомментирована. Часть файла alembic.ini
#sqlalchemy.url = driver://user:pass@localhost/dbnameВ файле env.py
- импортируем путь
import os
import sys
sys.path.append(os.getcwd())Импортируем настройки, создаем строку соединения и создаем закоментированный ранее в файле alembic.ini параметр sqlalchemy.url
from conf.settings.base import mysettings
connstring = "postgresql+psycopg2://{db_username}:{db_password}@{db_host}:{db_port}/{db_name}".format(
db_username=mysettings.db_username,
db_password=mysettings.db_password,
db_host=mysettings.db_host,
db_port=mysettings.db_port,
db_name=mysettings.db_name
)
config.set_main_option(name="sqlalchemy.url", value=connstring)
Импортируем db.initializer и создаем метаданные
import db.initializer
target_metadata = db.initializer.Base.metadataОстальные параметры оставляем неизменными. Результирующий файл настроек окружения alembic env.py:
from logging.config import fileConfig
import os
import sys
from sqlalchemy import engine_from_config
from sqlalchemy import pool
from alembic import context
from conf.settings.base import mysettings
sys.path.append(os.getcwd())
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
config = context.config
# Interpret the config file for Python logging.
# This line sets up loggers basically.
if config.config_file_name is not None:
fileConfig(config.config_file_name)
connstring = "postgresql+psycopg2://{db_username}:{db_password}@{db_host}:{db_port}/{db_name}".format(
db_username=mysettings.db_username,
db_password=mysettings.db_password,
db_host=mysettings.db_host,
db_port=mysettings.db_port,
db_name=mysettings.db_name
)
config.set_main_option(name="sqlalchemy.url", value=connstring)
# add your model's MetaData object here
# for 'autogenerate' support
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
import db.initializer
target_metadata = db.initializer.Base.metadata
# other values from the config, defined by the needs of env.py,
# can be acquired:
# my_important_option = config.get_main_option("my_important_option")
# ... etc.
def run_migrations_offline() -> None:
"""Run migrations in 'offline' mode.
This configures the context with just a URL
and not an Engine, though an Engine is acceptable
here as well. By skipping the Engine creation
we don't even need a DBAPI to be available.
Calls to context.execute() here emit the given string to the
script output.
"""
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""Run migrations in 'online' mode.
In this scenario we need to create an Engine
and associate a connection with the context.
"""
connectable = engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(
connection=connection, target_metadata=target_metadata
)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
Обновление конфигурации таблиц
Для проверки создаем первую пустую миграцию. После ее выполнения создастся таблица alembic_version
alembic revision -m "Empty Init"В данный момент фактического соединения с БД не было. В папке versions сформируется файл вида <id>_empty_init.py
После выполнения команды
alembic upgrade headв таблице alembic_version появится одна запись - идентификатор текущей версии базы данных.
Сейчас в папке db создаем папку tablesdefinition. В ней будем хранить файлы описаний таблиц и методы для работы с таблицами. Создадим файл userprofile.py
'''Definition tables of userprofile'''
import logging
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import sessionmaker
import db.initializer
from db.initializer import engine
def create_userprofile_class(Curbase):
class Userprofile(Curbase):
'''Class Userprofile definition'''
__tablename__ = 'userprofile'
user_id = Column(Integer(), primary_key=True)
username = Column(String(15), nullable=False, unique=True)
password = Column(String(255), nullable=False)
email = Column(String(255))
name = Column(String(100))
second_name = Column(String(100))
photo = Column(String(255))
balance = Column(Integer())
return Userprofile
def create_one_userprofile(username, password, email='', name='',
second_name='', photo='', balance=0):
''' Create one userprofile '''
try:
with engine.connect():
Session = sessionmaker(bind=engine)
with Session() as sess:
upelem = db.initializer.userprofile(username=username, password=password,
email=email, name=name, second_name=second_name,
photo=photo, balance=balance)
sess.add(upelem)
sess.commit()
except Exception as e:
logging.error(e)И в файле initializer.py после инициализации переменной Base добавим раздел инициализации описания таблицы
#============================ Creation classes definitions =========================
# === Import Userprofile class ===
from db.tablesdefinition.userprofile import create_userprofile_class
userprofile = create_userprofile_class(Base)
# ==================================================================================Теперь после выполнения команды
alembic revision --autogenerate -m "Added userprofile model"будет автоматически сгененрирован файл миграции, и после
alembic upgrade headсоздастся таблица userprofile.
P.s. В точке входа необходимо полностью импортировать initializer иначе будет ошибка, пример:
'''Main learning module'''
import logging
from db import initializer
from db.tablesdefinition.userprofile import create_one_userprofile
logging.basicConfig(level=logging.INFO,
filename='error.log',
format="%(levelname)s %(message)s")
if __name__ == '__main__':
create_one_userprofile(username = 'first6',
password = 'first',
balance = 1)Alembic
Установка и настройка
Стандартная установка:
pip install alembicПервая инициализация: alembic init folder_for_dbdata
alembic init alembicБудет создан файл alembic.ini и директория в соответствии с названием.
В alembic.ini обновляем параметр sqlalchemy.url
В файл env.py добавляем код
import os
import sys
sys.path.append(os.getcwd())
from app.db import Base
target_metadata = Base.metadata
Миграции
Создание первой (пустой) миграции.
После создания пустой миграции, в БД создастся таблица alembic_version в которой хранится идентификатор текущей версии.
alembic revision -m "Empty Init"Обновление базы данных после создания миграции
alembic upgrade headХэш текущей миграции
alembic currentИстория миграций.
Считываются все файлы миграций. Т.е. в случае загрузки предыдущего состояния, последующие миграции будут отображаться до тех пор, пока ненужные файлы миграций не будут удалены.
alembic historyВозврат к предыдущему состоянию
alembic downgrade migration_idДля возврата в стартовое состояние, нужно выполнить
alembic downgrade baseЕсли что-то пошло не так, для возврата в нулевое состояние нужно удалить из таблицы alembic_version текущий номер.
DELETE FROM public.alembic_version;Пропуск состояния
alembic stamp migration_idЭкспорт в формате sql
alembic upgrade migration_id_start:migration_id_stop --sql > migration.sqlАвтогенерация миграции
alembic revision --autogenerate -m "Added Cookie model"Поддерживаемые и неподдерживаемые действия при автоматической миграции
| Тип элемента | Поддерживаемые | Неподдерживаемые |
| Таблицы | Добавление и удаление | Изменение имени |
| Столбец | Добавление, удаление, изменение нулевого статуса на столбце | Изменение имени |
| Индекс | Основные изменения в индексах и явно обозначенных уникальных ограничениях, поддержка автоматической генерации индексов и уникальных ограничений |
|
| Ограничения | Ограничения без явного имени | |
| Ключи | Переименование | |
| Типы | Типы, которые явно не поддерживаются базой данных |
Чтобы alembic увидел класс данных, необходимо его непосредственно импортировать. Импорт всей директории не работает.
Ручное создание миграций
На примере изменения имени таблицы
- Изменить имя.
- Выполнить генерацию миграции
alembic revision -m "Renaming table"- В созданном файле изменить upgrade/downgrade
def upgrade():
op.rename_table('old_name', 'new_name')
def downgrade():
op.rename_table('new_name', 'old_name')- Выполнить миграцию
alembic upgrade headКоманды alembic
| add_column | Добавить столбец |
| alter_column | Изменить тип столбца, имя или значение по-умолчанию |
| create_check_constraint | Добавить ограничение |
| create_foreign_key | Добавить внешний ключ |
| create_index | Создать индекс |
| create_primary_key | Создать основной ключ |
| create_table | Создать таблицу |
| create_unique_constraint | Создать ограничение уникальности |
| drop_column | Удалить столбец |
| drop_constraint | Удалить ограничение |
| drop_index | Удалить индекс |
| drop_table | Удалить таблицу |
| execute | Выполнить сырую SQL команду |
| rename_table | Переименовать таблицу |
Модули
Pip, описание модулей
Альтернативные зеркала
Возможны случаи, когда это потребуется.
pip install <package> -i <hostname>
Например
pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple| Адрес репозитория | Тип |
|
https://pypi.org/simple
|
Основной репозиторий |
| https://pypi.tuna.tsinghua.edu.cn/simple | Вроде очень стабильный репозиторий |
| https://mirrors.aliyun.com/pypi/simple | Европейский вариант |
[global]
index-url = https://pip.ya.ru/simple
trusted-host = pip.ya.ruХранение конфигурации
Configparser стандартная библиотека для чтения и записи .ini файлов. Инструкция 1
Jsonschema модуль для проверки соответствия json существующей схеме. Документация
Libsettings модуль на основе jsonschema для чтения конфигурации из json файла и проверки конфигурации на соответствие схеме. Gitverse проекта
import logging
from libsettings import Jsettings
logging.basicConfig(level=logging.ERROR,
filename='error.log',
format="%(levelname)s %(message)s")
mysettings = Jsettings(settingsfname='mysettings.json',
schemafname='myschema.json')
mysettings.load_settings()jsonschema
Используется для валидации json схемы. По умолчанию дополнительно указанные ключи (не существующие в схеме, но присутствующие в документе) не проверяются.
Установка
pip install jsonschemaБазовое использование
from jsonschema import validate
validate(instance=json_to_check, schema=schema)
Исключения
jsonschema.exceptions.ValidationError - если документ не соответствует структуре
jsonschema.exceptions.SchemaError - если сама схема некорректна
Пример схемы:
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "number"},
},
"required": ["name"],
}Данная схема определяет json объект с 2 свойствами: name и age. Обязательное свойство name.
Ключевые слова
Для некоторых типов используются дополнительные ключевые слова.
| Ключевое слово | Описание |
| type |
Тип. Для корня часто object. string - строка number - число object - объект array - список |
| $defs | Вложенный шаблон для случая, когда шаблон элемента встречается в нескольких местах. |
| $ref | Подстановка вложенного шаблона. |
| $schema | Ссылка на шаблон шаблона. При обновлении версии библиотеки будет использоваться новый шаблон шаблона, что может привести к проблемам. Желательно указывать. |
Дополнительные ключевые слова для типов.
Тип array
| Ключевое слово | Описание |
| items |
Тип элементов списка. |
| minItems | Минимальное количество элементов |
Тип object
| Ключевое слово | Описание |
| required |
Список обязательных ключей. |
| properties |
Определяет ключи объекта и их тип. |
| additionalProperties |
Если True, то дополнительно указанные ключи приводят к исключению. |
Локальные вложенные шаблоны.
Для определения используется переменная $defs, для использования - $ref.
schema = {
"type": "object",
"properties": {
"address": {"$ref": "#/$defs/address"},
},
"$defs": {
"address": {
"type": "object",
"properties": {
"street": {"type": "string"},
}
},
},
}Pydantic 2
Описание
Библиотека валидации (проверка на соответствие типов) и трансформации (автоматическое приведение к нужным типам и форматам) данных.
Модели наследуются от класса BaseModel. Модель описывает набор полей, представляющих структуру данных и условия валидации.
Установка
pip install pydanticТипизация:
- Простая: указание типа, например, name: str.
- Объект Field(): дополнительные параметры, например, значения по умолчанию, ограничения и т.д.
Внутри класса можно комбинировать способы типизации.
from pydantic import BaseModel, Field
class User(BaseModel):
name: str
email: str = Field(..., alias='email_address')Валидация:
- Минимальная валидация: встроенные типы Python (например, str, int).
- Валидаторы: например EmailStr для проверки email-адресов. Требуется установка дополнительных зависимостей: pydantic[email] или pydantic[all].
- @field_validator — добавляет логику валидации поля. Вызывается при создании или изменении модели.
from pydantic import BaseModel, field_validator
class User(BaseModel):
age: int
@field_validator('age')
def check_age(cls, value):
if value < 18:
raise ValueError('Возраст должен быть больше 18 лет')
return value- @computed_field — вычисляемое поле на основе данных в модели. Его можно использовать для автоматической генерации значений, а также для валидации.
from pydantic import BaseModel, computed_field
class User(BaseModel):
name: str
surname: str
@computed_field
def full_name(self) -> str:
return f"{self.name} {self.surname}"- @model_validator - валидация всей модели.
Работает со всей моделью (а не с отдельными полями), может изменять данные перед валидацией (mode='before') или после (mode='after'), полезен для комплексных проверок, где одно поле зависит от другого, может возвращать новую версию модели (если нужно модифицировать данные).
@model_validator(mode='before')
def validate_before(cls, data: dict):
if 'username' not in data:
data['username'] = "guest_" + str(data.get('id', 0))
return data@model_validator(mode='after')
def validate_after(self):
if self.age < 18 and self.is_premium:
raise ValueError("Minors cannot have premium accounts!")
return selfПри проверке before передается класс, при after - объект. Можно делать два валидатора: before для подстановки вычисляемых значений и after для финальной проверки
Интеграция с SQLAlchemy:
Для настройки используется параметр ConfigDict с флагом from_attributes=True.
from datetime import date
from pydantic import BaseModel, ConfigDict
class User(BaseModel):
id: int
name: str = 'John Doe'
birthday_date: date
config = ConfigDict(from_attributes=True)Для создания модели Pydantic из объекта ORM используется метод from_orm.
user = User.from_orm(orm_instance)Ссылки:
Pyinstaller
Установка:
python -m pip install pyinstallerИспользование
pyinstaller [параметры] script.pyПараметры
| Параметр | Описание |
| --onefile | собирает всё в один .exe файл |
| --windowed | скрывает консоль (если у вас GUI-приложение). Если нужна консоль, уберите этот флаг. |
| --icon=ваша_иконка.ico | иконка |
| --name "МояПрограмма" | имя программы |
| --dest <путь_к_директории> | директория, в которую будет собираться exe файл |
Telegram
При взаимодействии с ботом нужен идентификатор.
Свой идентификатор
- В Telegram напиши боту @userinfobot
- Он ответит твоим
user_id(число). Это и есть твойchat_id.
Для групп или каналов
- Добавь бота в группу/канал.
- Напиши любое сообщение.
- В браузере открой: https://api.telegram.org/bot<YOUR_BOT_TOKEN>/getUpdates
- В JSON-ответе найди
chat":{"id": ... }— это и естьCHAT_ID. Для супергрупп он будет вида-1001234567890.
Bitcoinlib
Библиотека для работы с кошельками. Операции, связанные с кошельком:
- + Создание нового кошелька
- Экспорт данных о созданном кошельке
- Импорт существующего кошелька
- + Информация о кошельке
- Транзакция
Создание кошелька. Создается хранилище данных в ~/.bitcoinlib Затем можно проводить операции.
def create_wallet():
# Создаем новый testnet кошелек
wallet = Wallet.create(
name='my_testnet_wallet',
network='testnet'
)
print(f"Адрес: {wallet.get_key().address}")
print(f"Приватный ключ (WIF): {wallet.get_key().wif}")
print(f"Баланс: {wallet.balance()} satoshi")
# Получить информацию об адресе
print(f"Это testnet адрес? {wallet.get_key().address.startswith(('m', 'n', '2', 'tb1'))}")Для получения стартовых btc в сети testnet использовал https://coinfaucet.eu/en/btc-testnet/
Информация о кошельке. Кошелек с данным названием уже установлен в системе.
def wallet_info():
"""Полная информация о кошельке (исправленная)"""
wallet = Wallet('my_testnet_wallet')
wallet.scan() # Важно: синхронизируем с сетью
print("=" * 60)
print(f"КОШЕЛЁК: {wallet.name}")
print(f"СЕТЬ: {wallet.network.name}")
print("=" * 60)
# Баланс
balance = wallet.balance()
print(f"\n💰 БАЛАНС: {balance:,} satoshi")
print(f" ≈ {balance / 100000000:.8f} BTC")
# UTXOs
utxos = wallet.utxos()
print(f"\n UTXOs: {len(utxos)}")
if utxos:
utxo_total = 0
for i, utxo in enumerate(utxos, 1):
print(f"\n UTXO #{i}:")
print(f" Транзакция: {utxo['txid'][:20]}...:{utxo['output_n']}")
print(f" Адрес: {utxo['address']}")
print(f" Сумма: {utxo['value']:,} sat")
if 'confirmations' in utxo:
confs = utxo['confirmations']
status = "✓ Подтверждено" if confs > 0 else " Ожидание"
print(f" Статус: {status} ({confs} подтверждений)")
utxo_total += utxo['value']
print(f"\n Сумма всех UTXOs: {utxo_total:,} sat")
# Транзакции
transactions = wallet.transactions()
print(f"\n ТРАНЗАКЦИИ: {len(transactions)}")
if transactions:
for tx in transactions:
print(f"\n Транзакция: {tx.txid[:20]}...")
print(f" Дата: {tx.date}")
if tx.confirmations:
print(f" Подтверждений: {tx.confirmations}")
else:
print(f" Статус: Неподтверждена")
print(f" Комиссия: {tx.fee} sat")
# Анализируем сумму
our_addresses = wallet.addresslist()
received = 0
sent = 0
# Выходы (получение)
for output in tx.outputs:
if output.address in our_addresses:
received += output.value
# Входы (отправка)
for input_tx in tx.inputs:
if input_tx.address in our_addresses:
sent += input_tx.value
if received > 0 and sent > 0:
print(f" Тип: Перевод")
print(f" Изменение баланса: {received - sent:,} sat")
elif received > 0:
print(f" Тип: Получение")
print(f" Сумма: +{received:,} sat")
elif sent > 0:
net_sent = sent - tx.fee
print(f" Тип: Отправка")
print(f" Сумма: -{net_sent:,} sat (включая комиссию)")
# Ключи и адреса
print(f"\n КЛЮЧИ И АДРЕСА:")
keys = wallet.keys()
print(f" Всего ключей: {len(keys)}")
used_addresses = [key.address for key in keys if key.used]
print(f" Использованных адресов: {len(used_addresses)}")
# Показываем первые 5 адресов
for i, key in enumerate(keys[:5], 1):
status = " Использован" if key.used else " Не использован"
print(f" {i}. {key.address} - {status} ({key.balance} sat)")
if len(keys) > 5:
print(f" ... и ещё {len(keys) - 5} адресов")
# Сетевая информация
print(f"\n СЕТЕВАЯ ИНФОРМАЦИЯ:")
#print(f" Последний блок: {wallet.last_block}")
print(f" ID кошелька: {wallet.wallet_id}")
return wallet
Логгирование
Встроенный модуль logging. Нужно настроить логгер и использовать его.
Настройка:
import logging
if __name__ == '__main__':
logging.basicConfig(level=logging.ERROR, filename="error.log",filemode="w",
format="%(asctime)s %(levelname)s %(message)s")Использование:
Внутри модуля, где настраивался логгер:
logging.error("Критическая ошибка в основном модуле")
В вызываемом модуле не проводим настройку, только:
logger = logging.getLogger(__name__)
logger.error('Wow')
Docsvision
Существует webapi
Узнать realm можно через ipconfig на win машине в домене, строка "DNS-суффикс подключения"
Список контроллеров домена: nslookup -type=SRV _ldap._tcp.<realm>
Для работы требуется
sudo apt install krb5-user
sudo apt install libkrb5-devФайл /etc/krb5.conf
[libdefaults]
default_realm = DOMAIN.LOCAL
dns_lookup_realm = true
dns_lookup_kdc = true
[realms]
DOMAIN.LOCAL = {
kdc = dc01.domain.local
admin_server = dc01.domain.local
}Для ручного получения тикета (REALM обязательно прописными!):
kinit username@REALMПроверка полученного тикета:
klistМодули python
b
Rabbitmq
Тестирование Playwright
Начало
Установка
python -m pip install playwrightПроверка установки
playwright --versionУстановка драйверов для браузеров
playwright install #Все браузеры
playwright install name #Только name браузеры
playwright install chromium #ChromeУстановка pytest
python -m pip install pytestУстановка плагина pytest-playwright
python -m pip install pytest-playwrightОписание
Два режима работы: синхронный и асинхронный. Для синхронного:
from playwright.sync_api import sync_playwrightДля асинхронного режима:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch()
page = await browser.new_page()
await page.goto("https://playwright.dev")
print(await page.title())
await browser.close()
asyncio.run(main())Чаще используется синхронный режим.
Запуск и закрытие браузера:
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.goto("https://playwright.dev/python")
docs_button = page.get_by_role('link', name="Docs")
docs_button.click()
browser.close()
headless=False обозначает визуальное открытие, slow_mo задержка
Использование интерактивной консоли
Иногда для удобства можно использовать консоль python для ручного тестирования покомандного ввода.
python
Python 3.13.1 (tags/v3.13.1:0671451, Dec 3 2024, 19:06:28) [MSC v.1942 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from playwright.sync_api import sync_playwright
>>> playwright = sync_playwright().start()
>>> browser = playwright.chromium.launch(headless=False, slow_mo=100)
>>> page = browser.new_page()
>>> browser.close()
>>> playwright.stop()Если создать docs_button, у нее будет метод highlight() для визуальной подсветки найденного элемента.
Локаторы
Локаторы: способ поиска элементов на странице. Поэтому они являются методами page
В VSC Ctrl+Click по методу выводит код метода.
| Локатор | Описание |
| page.get_by_role('link', name="Docs") |
Поиск элемента по роли name - текст link <a> heading <h> radio, checkbox, button |
| page.get_by_label("Email address") | Для выделения элементов, у которых есть привязанная метка. Например
|
| page.get_by_placeholder("Enter email") | Поиск элементов по placeholder |
| page.get_by_text("Something", exact=False) | Поиск по тексту. Exact=False ищет вхождение. |
| page.get_by_alt_text(text) | Поиск по атрибуту alt у изображений |
| page.get_by_title(text) | Атрибут title |
| page.locator(text) |
Поиск по CSS. Можно использовать tagname, classname, id, attribute/value Примеры^ css=h1 footer <tagname>.<classname> button.btn-outline-sucess <tagname>#<idname> button#BtnGroupDrop1 <tagname>[attribute] input[readonly] <tagname>[attribute=somevalue] input[value='correct value'] |
|
Поиск по иерархии элементов. Если через пробелы-то вложенные элементы. Если через точку - то у элемента несколько классов. Но они не обязательно непосредственно вложенные. nav.bg-dark a.nav-link.active Для непосредственного вложения: nav.bg-dark > a.nav-link.active |
|
|
Называются sudo классами, Класс и текст в теге. Для вхождения: h1:text('Navbars') Для полного соответствия: h1:text-is('Navbars') div.dropdown-menu:visible Для определения по номеру вхождения, когда их много :nth-match(button.btn-primary, 4) |
|
|
XPath Абсолютный путь: xpath=/html/head/title С любого начала: xpath=//h1/h2 С указанием атрибута xpath=//h1[ @id='navbars' ] |
|
|
Функции XPath Для поиска по тексту, точно: //h1[text()='Headling1'] Для поиска по тексту, содержит: //h1[contains(text(), 'Headling1')] Для поиска по тексту, содержит: //h1[contains(@class, 'btn')] |
|
| Множественные условия |
Поиск родительского элемента page.get_by_label("Email address").locator("..") Фильтрация page.get_by_role("heading").filter(has_text="First") По дочернему элементу page.locator("div.form-group").filter(has=page.get_by_label("Password")) |
Доступ к iframe
'''Test for auth module'''
import pytest
from playwright.sync_api import Browser, Page, expect
AUTH_URL = "https://wood.bobrobotirk.ru/auth"
@pytest.fixture
def page_and_auth(browser: Browser):
context = browser.new_context(
storage_state="playwright/.auth/vk.json"
)
page = context.new_page()
yield page
context.close()
def test_first(page_and_auth: Page):
page_and_auth.goto(AUTH_URL)
vkframe = page_and_auth.frame(url=lambda url: "id.vk.com" in url)
if vkframe:
authbutton = vkframe.get_by_role("button", name="Продолжить как")
expect(authbutton, "Кнопка Продолжить как... отсутствует").to_be_visible(timeout=20000)
authbutton.click()
back_button = page_and_auth.get_by_role("button", name="Авторизация успешна")
expect(back_button, "Сервис не произвел авторизацию").to_be_visible()
back_button.click()
else:
assert False, "VK фрейм не найден."Actions
| Действие | Описание |
| click() |
Однократное нажатие. Опции: button="left" modifiers=["Shift", "Alt"] с зажатой кнопкой Shift timeout=2_000 Задержка перед ошибкой. Обычно 30 сек. force=True Ошибка сразу же если не найден. |
| dblclick() |
Двойной щелчок. Опции как у click +: delay=100 - задержка в миллисекундах
|
| hover() | Навести мышь на выбранный элемент |
| fill("my text") | Заполнить поле ввода текстом my text. Аналогично Ctrl-V |
| clear() | Очистить поле ввода |
| type("my text", delay=100) | Имитация побуквенного ввода |
|
check() Еще: set_checked(True) |
Выбор radiobutton, checkbox, switch is_checked() для checkbox проверяет, выбран ли checkbox |
| uncheck() |
убрать выбор |
| select_option("text") |
Выбор опции из раскрывающегося списка. Но если отсутствует - будет Timeout Error. Если передать список - будет множественный выбор. |
|
Для раскрытия Dropdown элемента: нажатие на него, выбор элемента и нажатие |
|
| set_input_files("") |
Для элемента позволяющего загружать файлы, имя файла из директории, из которой запускается скрипт. Можно передать список. |
|
Если по кнопке открывается меню выбора файла, то
|
|
|
press("KeyW") press("Shift+KeyW") press("Control+ArrowLeft") |
События (Events)
События в page.goto
В переменной wait_until.
- load: загрузка всего контента
- domcontentloaded: загрузка dom
- commit: при получении ответа от сервера
- networkidle: до завершения всех событий сети. Для динамического контента не меньше чем load.
Можно считать время загрузки.
from playwright.sync_api import sync_playwright
from time import perf_counter
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
print('Page loading...')
start = perf_counter()
page.goto("https://playwright.dev/python", wait_until='load')
delta = perf_counter() - start
print(f'Page loaded in {delta} s.')
browser.close()События динамического контента (React, ...)
Находим динамический элемент, кликаем по нему и при помощи wait_for() ждем.
from playwright.sync_api import sync_playwright
from time import perf_counter
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.goto("https://www.scrapethissite.com/pages/ajax-javascript/", timeout=60_000)
mylink = page.get_by_role("link", name="2014")
mylink.click()
print('Loading movie...')
start = perf_counter()
loadedcont = page.locator("td.film-title").first
loadedcont.wait_for()
delta = perf_counter() - start
print(f'Movie loaded in {delta} s.')
browser.close()
Ожидание события.
Указываем тип события и функцию, выполняемую при наступлении события.
from playwright.sync_api import sync_playwright
def onload(page):
print("Page loaded", page)
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.on("load", onload)
page.goto("https://bootswatch.com/default")
browser.close()Пример просмотра событий запросов
from playwright.sync_api import sync_playwright
def onrequest(request):
print("Request send: ", request)
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.on("request", onrequest)
page.goto("https://bootswatch.com/default")
browser.close()
Вывод:
Request send: <Request url='https://bootswatch.com/default' method='GET'>
Request send: <Request url='http://bootswatch.com/default/' method='GET'>
Request send: <Request url='https://bootswatch.com/default/' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/bootstrap/dist/css/bootstrap.css' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/bootstrap-icons/font/bootstrap-icons.min.css' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/prismjs/themes/prism-okaidia.css' method='GET'>
Request send: <Request url='https://bootswatch.com/_assets/css/custom.min.css' method='GET'>
Request send: <Request url='https://www.googletagmanager.com/gtag/js?id=G-KGDJBEFF3W' method='GET'>
Request send: <Request url='https://cdn.carbonads.com/carbon.js?serve=CKYIE23N&placement=bootswatchcom' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/bootstrap/dist/js/bootstrap.bundle.min.js' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/prismjs/prism.js' method='GET'>
Request send: <Request url='https://bootswatch.com/_assets/js/custom.js' method='GET'>
Request send: <Request url='https://bootswatch.com/_vendor/bootstrap-icons/font/fonts/bootstrap-icons.woff2?1fa40e8900654d2863d011707b9fb6f2' method='GET'>
Request send: <Request url='https://www.google-analytics.com/g/collect?v=2&tid=G-KGDJBEFF3W>m=45je54g0v9135688085za200&_p=1744912703288&gcd=13l3l3l3l1l1&npa=0&dma=0&tag_exp=102509682~102803279~102813109~102887800~102926062~103027016~103051953~103055465~103077950~103106314~103106316~103130495~103130497&cid=128797986.1744912704&ul=ru-ru&sr=1280x720&uaa=x86&uab=64&uafvl=Not%253AA-Brand%3B24.0.0.0%7CChromium%3B134.0.6998.35&uamb=0&uam=&uap=Windows&uapv=10.0.0&uaw=0&are=1&frm=0&pscdl=noapi&_s=1&sid=1744912703&sct=1&seg=0&dl=https%3A%2F%2Fbootswatch.com%2Fdefault%2F&dt=Bootswatch%3A%20Default&en=page_view&_fv=1&_nsi=1&_ss=1&_ee=1&tfd=2018' method='POST'>
Request send: <Request url='https://srv.carbonads.net/ads/CKYIE23N.json?segment=placement:bootswatchcom&v=true' method='GET'>Есть событие при выборе файла.
Удаление прослушивания события: page.remove_listener("name_event", func)
События всплывающих окон (alert, confirm, prompt)
Событие page.on("dialog", func), устанавливаем ожидание до возможного появления окна.
Функция:
def on_dialog(dialog)
dialog.accept()
dialog.dismiss()Если диалог prompt, то для заполнения поля ввода в функции accept нужно добавить строковую переменную.
def on_dialog(dialog)
dialog.accept("Text for enter")Событие скачивания файла
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.goto("https://bootswatch.com/default")
btn = page.get_by_role("link", name="Download me")
with page.expect_download() as download_info:
btn.click()
download = download_info.value
download.save_as(fname)
browser.close()Второй вариант: добавить listener
from playwright.sync_api import sync_playwright
def saving_func(download):
fname = "first.jpg"
download.save_as(fname)
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=False, slow_mo=500)
page = browser.new_page()
page.goto("https://bootswatch.com/default")
page.once("download", saving_func)
btn = page.get_by_role("link", name="Download me")
with page.expect_download() as download_info:
btn.click()
browser.close()
Аутентификация
При 2FA аутентификации возникают проблемы при повторном исполнении скрипта. Для обхода этого используют контекст браузера.
Шаг 1. Сохранение контекста.
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.firefox.launch(headless=False, slow_mo=500)
context = browser.new_context()
page = context.new_page()
page.goto("https://vk.ru")
page.pause() # Откроется доп. окно. Проходим авторизацию, в доп.окне play
context.storage_state(path="playwright/.auth/vk.json")
context.close()Шаг 2. Использование контекста
from playwright.sync_api import sync_playwright
with sync_playwright() as playwright:
browser = playwright.firefox.launch(headless=False, slow_mo=500)
context = browser.new_context(storage_state="playwright/.auth/vk.json")
page = context.new_page()
page.goto("https://vk.ru")
page.pause() #в реальных скриптах это убирается)
context.close()
Pytest & Playwright
Pytest
Имена файлов тестов должны иметь префикс test_ или постфикс _test. Имена тестов должны иметь префикс test_
В модуле utils функция root, отнимающая 1 от входного параметра. Пример теста:
import utils
def test_first():
num24 = utils.root(25)
assert num24 == 24Запуск теста:
pytest second_test.pyКлюч -v отображает расширенную информацию.
Ключ -s разрешает вывод данных из тестируемых функций.
Запуск без указания имени файла исполняет все тесты.
Желательно определение типов в функциях.
Виды проверок
| Проверка | Описание |
| assert mynum == 32 | Проверка на значение |
| assert type(dt) == dict | Проверка типа |
| assert "timestamp" in dt_list | Проверка присутствия в списке |
Для вывода доп. информации:
assert mynum == 32, "Число mynum должно быть равно 32"Фикстуры:
Для упаковки повторяющихся действий.
import json
import report
import pytest
@pytest.fixtures
def report_json():
report.generate_report()
with open("report.json") as file:
return json.load(file)
def test_report_json(report_json):
assert type(report_json) == dictФикстура исполняется каждый раз при вызове. Для однократного исполнения фикстуры нужно добавить scope="session"
import json
import report
import pytest
@pytest.fixtures(scope="session")
def report_json():
report.generate_report()
with open("report.json") as file:
return json.load(file)
def test_report_json(report_json):
assert type(report_json) == dictВиды scope
| session | Один раз в пределах сессии |
| function | Каждый раз |
| module | Если несколько тестовых файлов, то один раз в пределе запуска. |
Pytest-playwright
Данный плагин упрощает работу с pytest. Встроенные фикстуры. Задачу создания и удаления playwright, browser берет на себя.
from playwright.sync_api import Page
def test_first(page: Page):
page.goto("https://playwright.dev/python")
link = page.get_by_role("link", name="GET STARTED")
link.click()
assert page.url == "https://playwright.dev/python/docs/intro"Настройка pytest
Через консоль:
- --headed Отображать окно
- --slowmo=500 Замедление работы
- --browser=firefox Настройка браузера
Через конфигурационный файл pytest.ini
[pytest]
addopts = --headed --slowmo=500 --browser=firefoxФикстуры
Добавить фикстуру
import pytest
from playwright.sync_api import Page
@pytest.fixture
def load_testpage(page: Page):
page.goto("https://playwright.dev/python")
return page
def test_first(load_testpage: Page):
link = load_testpage.get_by_role("link", name="GET STARTED")
link.click()
assert load_testpage.url == "https://playwright.dev/python/docs/intro"Автоматическое исполнение фикстуры перед каждой функцией:
import pytest
from playwright.sync_api import Page
@pytest.fixture(autouse=True)
def load_testpage(page: Page):
page.goto("https://playwright.dev/python")
return page
def test_first(page: Page):
link = page.get_by_role("link", name="GET STARTED")
link.click()
assert page.url == "https://playwright.dev/python/docs/intro"Пред и пост исполнение кода:
import pytest
from playwright.sync_api import Page
@pytest.fixture(autouse=True)
def load_testpage(page: Page):
page.goto("https://playwright.dev/python")
yield page
page.goto("https://yandex.ru")
def test_first(page: Page):
link = page.get_by_role("link", name="GET STARTED")
link.click()
assert page.url == "https://playwright.dev/python/docs/intro"Пример проверки авторизации ВК
'''Test for auth module'''
import pytest
from playwright.sync_api import Browser, Page, expect
AUTH_URL = "https://wood.bobrobotirk.ru/auth"
@pytest.fixture
def page_and_auth(browser: Browser):
context = browser.new_context(
storage_state="playwright/.auth/vk.json"
)
#page = context.new_page()
yield context
context.close()
def get_cookie(all_cookies, cname):
val = next((cookie['value'] for cookie in all_cookies if cookie.get('name') == cname), None)
return val
def test_first(page_and_auth: Browser):
page = page_and_auth.new_page()
page.goto(AUTH_URL)
vkframe = page.frame(url=lambda url: "id.vk.com" in url)
if vkframe:
authbutton = vkframe.get_by_role("button", name="Продолжить как")
expect(authbutton, "Кнопка Продолжить как... отсутствует").to_be_visible(timeout=20000)
authbutton.click()
back_button = page.get_by_role("button", name="Авторизация успешна")
expect(back_button, "Сервис не произвел авторизацию").to_be_visible()
back_button.click()
all_cookies = page_and_auth.cookies()
session_id_value = get_cookie(all_cookies, 'session_id')
assert session_id_value, "Cookie session_id не установлен."
else:
assert False, "VK фрейм не найден."Дополнительные возможности
Скриншоты
Скрин страницы
page.screenshot(path="", full_page=True)
Скрин элемента тоже работает.
link.screenshot(path="")
Запись видео
from playwright.sync_api import Browser
def test_first(browser: Browser):
context = browser.new_context(
storage_state="playwright/.auth/vk.json",
record_video_dir="video/"
)
page = context.new_page()
page.goto("https://playwright.dev/python")
link = page.get_by_role("link", name="GET STARTED")
link.click()
assert page.url == "https://playwright.dev/python/docs/intro"
page.goto("https://vk.ru")Вариант с текстурой:
import pytest
from playwright.sync_api import Browser, Page
@pytest.fixture
def recordable(browser: Browser):
context = browser.new_context(
storage_state="playwright/.auth/vk.json",
record_video_dir="video/"
)
page = context.new_page()
yield page
context.close()
def test_first(recordable: Page):
recordable.goto("https://playwright.dev/python")
link = recordable.get_by_role("link", name="GET STARTED")
link.click()
assert recordable.url == "https://playwright.dev/python/docs/intro"
recordable.goto("https://vk.ru")Трассировка данных
Создание трассировки:
import pytest
from playwright.sync_api import Page, BrowserContext
@pytest.fixture(autouse=True)
def trace_test(context: BrowserContext):
context.tracing.start(
name="playwrite",
screenshots=True,
snapshots=True,
sources=True
)
yield
context.tracing.stop(path="trace.zip")
def test_first(page: Page):
page.goto("https://playwright.dev/python")
link = page.get_by_role("link", name="GET STARTED")
link.click()
assert page.url == "https://playwright.dev/python/docs/intro"Просмотр трассировки
playwright show-trace trace.zipЗапись действий
Старт записи
playwright codegen playwright.devВ окне кода есть поле Target, позволяет переключать тип библиотек (playwright sync/async, pytest). Потом сохраняем полученную последовательность и устанавливаем нужные условия для проверки.
Ожидание
from playwright.sync_api import Page, expect
DOCS_URL = "https://playwright.dev/python/docs/intro"
def test_first(page: Page):
page.goto("https://playwright.dev/python")
link = page.get_by_role("link", name="GET STARTED")
link.click()
#assert page.url == DOCS_URL
expect(page).to_have_url(DOCS_URL)| expect(page).to_have_url | наличие url |
| expect(page).to_have_title | наличие title |
|
link = page.get_by_role("link", name="GET STARTEDer")
expect(link).to_be_visible()
|
Видимость элемента в переменной link |
|
expect(link).to_be_enabled()
|
Доступный элемент |
|
expect(heading).to_contain_text()
|
Присутствие текста (часть) |
|
expect(heading).to_have_text()
|
Присутствие текста (полное совпадение) |
|
expect(mylink).to_have_class()
|
Наличие класса у элемента Несколько классов: "class1 class2" Должно быть полное соответствие. Но можно использовать регулярки. |
|
expect(mylink).to_have_id()
|
Наличие id |
|
expect(mylink).to_have_attribute(attr_name, attr_value)
|
Наличие атрибута. При необходимости можно указать значение атрибута. |
|
expect(mylink).to_be_editable()
|
|
|
expect(mylink).to_be_empty()
|
|
|
expect(mycheckbox).to_be_checked()
|
|
|
expect(mymenu).to_have_value()
|
Элемент в меню выбора |
|
expect(mymultimenu).to_have_values([])
|
Несколько выбранных |
not_ - префикс отрицания
Pytest
Теория
- Модульное: небольшой элемент/модуль
- Компонентное: проверка подсистем по отдельности
- Альфа/бета: в реальных условиях на настоящих данных в прод версии
- Комплексное: проверка связей интерфейсов между парами и группами компонентов
- Системное: поведение как в целом, так и в частности
- ПСИ: проверка удовлетворения системы требованиям
- Пилотное: опытная эксплуатация под тщательным контролем
- Планирование тестирования - описывает все процессы. Понимание места тестирования
- операционный и организационный контекст
- Риски качества системы + ранжирование, понимание каждого возможностей тестирования для смягчения рисков
- Потребности временнЫх ресурсах
- План мероприятий по тестированию. Задачи, состав участников.
Важно Ожидание качества (численные критерии, предьявляемые перед началом) и Опыт качества (численное значение критериев после выполнения работ). Жизненный цикл системы = Жизненный цикл разработки + эксплуатации
- Подготовка к тестированию
- Обучение тестировщиков до нужного уровня
- Спроектировать систему тестирования (окружение, процедура, распределение задач, )
- Проведение тестирования
- Получение версии для тестирования
- Проведение тестов
Предпочтительнее алгоритм Дано-Ожидаемо-Проверка Лучше пофункциональное тестирование. Интегральные тесты хороши но не дают нужной детализации. Каждый тест должен возвращать состояние в начальное, они должны быть последовательно-независимыми
- Совершенствование
- Документирование тестирования
- Информирование о результатах
- При изменении контекста изменение процесса
- Что делает группа тестирования, когда применяет успешный процесс, и какие преимущества она получает.
- Нереалистичные ожидания со стороны руководства
- Получить согласие на изменение процесса сложнее самого изменения
- Процесс усовершенствования требует наличия плана
- Точка тестирования:
- Итоговая цель тестирования:
- Краткосрочная цель и параметры тестирования:
- Документирование:
- Фиксирование версионности:
- Приоретизация тестирования:
- Параметры тестируемой подсистемы:
- Блоки:
- Функции в каждом блоке:
- Переменные каждой функции:
- Комбинированные ожидаемые результаты каждой функции от переменной:
def test_passing():
assert (1, 2, 3) == (1, 2, 3)def assert_identical(c1: Card, c2: Card):
__tracebackhide__ = True
assert c1 == c2
if c1.id != c2.id:
pytest.fail(f'id\'s don\'t match. {c1.id} != {c2.id}')def test_no_path_raises():
with pytest.raises(TypeError):
cards.CardsDB()def test_raises_with_info():
match_regex = "missing 1 .* positional argument"
with pytest.raises(TypeError, match=match_regex):
cards.CardsDB()def test_raises_with_info_alt():
with pytest.raises(TypeError) as exc_info:
cards.CardsDB()
expected = "missing 1 required positional argument"
assert expected in str(exc_info.value)import pytest
@pytest.fixture()
def some_data():
"""Return answer to ultimate question."""
return 42
def test_some_data(some_data):
"""Use fixture return value in a test."""
assert some_data == 42@pytest.fixture()
def cards_db():
# setup part
with TemporaryDirectory() as db_dir:
db_path = Path(db_dir)
db = cards.CardsDB(db_path)
# end setup part, return db object
yield db
# closing db after testing
db.close()
def test_empty(cards_db):
# in cards_db - db object, we can use it
assert cards_db.count() == 0pytest --fixtures -v расположение файла#ch3/a/conftest.py
from pathlib import Path
from tempfile import TemporaryDirectory
import cards
import pytest
@pytest.fixture(scope="session")
def cards_db():
"""CardsDB object connected to a temporary database"""
with TemporaryDirectory() as db_dir:
db_path = Path(db_dir)
db = cards.CardsDB(db_path)
yield db
db.close()
#ch3/a/test_count.py
import cards
def test_empty(cards_db):
assert cards_db.count() == 0
def test_two(cards_db):
cards_db.add_card(cards.Card("first"))
cards_db.add_card(cards.Card("second"))
assert cards_db.count() == 2 @pytest.fixture(scope="session")
def db():
"""CardsDB object connected to a temporary database"""
with TemporaryDirectory() as db_dir:
db_path = Path(db_dir)
db_ = cards.CardsDB(db_path)
yield db_
db_.close()
@pytest.fixture(scope="function")
def cards_db(db):
"""CardsDB object that's empty"""
db.delete_all()
return db#ch3/c/conftest.py
@pytest.fixture(scope="function")
def non_empty_db(cards_db, some_cards):
...
Asyncio
Сопрограммы
ЭТО ТЕХНОЛОГИЯ УСКОРЕНИЯ РАБОТЫ В ОДНОМ ПОТОКЕ. ДЛЯ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ THREADING,
Сопрограммы - функции с возможностью приостановки при длительной внешней операции. Async определяет сопрограмму, await приостанавливает сопрограмму на время выполнения внешней задачи. При вызове сопрограммы она напрямую не выполняется. Для старта нужна точка входа в асинхронные вычисления.
Пример: правильное использование.
import asyncio
async def corutine_add_one(a: int) -> int:
return b + 1
corutine_res = asyncio.run(corutine_add_one(5))
print(type(corutine_res), ' ', corutine_res)Однако если просто запустить корутину, то результат будет интересным:
import asyncio
async def corutine_add_one(a: int) -> int:
return b + 1
corutine_res = corutine_add_one(5)
print(type(corutine_res), ' ', corutine_res)Вывод:
<class 'coroutine'> <coroutine object corutine_add_one at 0x0000026850FD4270>Существует цикл событий. При постановке корутины на паузу задача передается следующей корутине. Однако такой код выполняется в виде простого синхронного кода:
import asyncio
async def sleep_10(x: int) -> int:
await asyncio.sleep(10)
return x+10
async def main():
x1 = await sleep_10(1)
x2 = await sleep_10(1)
print(x1, ' ', x2)
asyncio.run(main())Задачи
Для приближения к параллельным вычислениям необходимо использовать задачи.
import asyncio
from util import delay
async def main():
sleep1 = asyncio.create_task(delay(10))
sleep2 = asyncio.create_task(delay(10))
await sleep1
await sleep2
asyncio.run(main())К тому же, если убрать await sleep2, то вторая задача все равно выполнится, т.к. вроде все задачи из очереди запускаются. Это так, вот только не говорится о том, завершаются они или нет. Вот пример кода:
async def delay(delay_seconds: int) -> int:
print(f'Засыпаю на {delay_seconds} секунд.')
await asyncio.sleep(delay_seconds)
print(f'сон в течение {delay_seconds} закончился.')
return delay_seconds
async def delay_with_inner(delay_seconds: int) -> int:
print(f'Засыпаю на {delay_seconds} секунд.')
t1 = asyncio.create_task(delay(15))
await asyncio.sleep(delay_seconds)
#await t1
print(f'сон в течение {delay_seconds} закончился.')
return delay_seconds
async def main():
sleep1 = asyncio.create_task(delay_with_inner(10))
sleep2 = asyncio.create_task(delay_with_inner(10))
sleep3 = asyncio.create_task(delay_with_inner(10))
await sleep1
await sleep2
await sleep3
asyncio.run(main())Если внешнюю мы запускаем на 10 секунд, то внутренняя (t1) тоже запускается - т.к. находится в очереди задач. Но вот только программа завершается до завершения t1.
Засыпаю на 10 секунд.
Засыпаю на 10 секунд.
Засыпаю на 10 секунд.
Засыпаю на 15 секунд.
Засыпаю на 15 секунд.
Засыпаю на 15 секунд.
сон в течение 10 закончился.
сон в течение 10 закончился.
сон в течение 10 закончился.И все! А если раскомментировать строку с ожиданием t1, то тогда сначала завершится t1
Засыпаю на 10 секунд.
Засыпаю на 10 секунд.
Засыпаю на 10 секунд.
Засыпаю на 15 секунд.
Засыпаю на 15 секунд.
Засыпаю на 15 секунд.
сон в течение 15 закончился.
сон в течение 15 закончился.
сон в течение 15 закончился.
сон в течение 10 закончился.
сон в течение 10 закончился.
сон в течение 10 закончился.А для такого кода будет создано 3 файла. Но если вместо sleep3 установить sleep1, то все задачи стартуют, но будет создан только файл 5.txt.
import asyncio
from util import delay_with_inner, delay, delay_and_writefile
from time import sleep
async def main():
sleep1 = asyncio.create_task(delay_and_writefile(5))
sleep2 = asyncio.create_task(delay_and_writefile(10))
sleep3 = asyncio.create_task(delay_and_writefile(11))
await sleep3
asyncio.run(main())Исходя из этого, важна не последовательность помещения в задачи, а последовательность при обращении (момент await).
Снятие задач и тайм-ауты
import asyncio
from asyncio import CancelledError
from util import delay
async def main():
long_task = asyncio.create_task(delay(10))
seconds_elapsed = 0
while not long_task.done():
print('Задача не закончилась, следующая проверка через секунду.')
await asyncio.sleep(1)
seconds_elapsed = seconds_elapsed + 1
if seconds_elapsed == 5:
long_task.cancel()
try:
await long_task
except CancelledError:
print('Наша задача была снята')
asyncio.run(main())
Тайм-аут:
import asyncio
from util import delay
async def main():
delay_task = asyncio.create_task(delay(2))
try:
result = await asyncio.wait_for(delay_task, timeout=1)
print(result)
except asyncio.exceptions.TimeoutError:
print('Тайм-аут!')
print(f'Задача была снята? {delay_task.cancelled()}')
asyncio.run(main())
При помощи shield можно игнорировать запросы на снятие:
import asyncio
from util import delay
async def main():
task = asyncio.create_task(delay(10))
try:
result = await asyncio.wait_for(asyncio.shield(task), 5)
print(result)
except TimeoutError:
print("Задача заняла более 5 с, скоро она закончится!")
result = await task
print(result)
asyncio.run(main())
Список задач:
for task in asyncio.tasks.all_tasks():
print(task)Множественные task в цикле.
Проблема: при создании в цикле при возникновении исключения в одной задаче, остальные задачи могут не завершить выполнение.
Функция gather
import asyncio
import aiohttp
from aiohttp import ClientSession
from chapter_04 import fetch_status
async def main():
async with aiohttp.ClientSession() as session:
urls = ['https://example.com' for _ in range(1000)]
requests = [fetch_status(session, url) for url in urls]
status_codes = await asyncio.gather(*requests)
print(status_codes)
asyncio.run(main())
Gather возвращает статусы в порядке передаче объектов, независимо от времени исполнения. Возвращает все данные одновременно.
Обработка исключений - необязательный bool параметр return_exceptions.
- return_exceptions=False по умолчанию. Если хотя бы одна сопрограмма возбуждает исключение, то gather возбуждает то же исключение в точке await. Но, даже если какая-то сопрограмма откажет, остальные не снимаются и продолжат работать при условии, что мы обработаем исключение и оно не приведет к остановке цикла событий и снятию задач;
- return_exceptions=True – в этом случае исключения возвращаются в том же списке, что результаты. Сам по себе вызов gather не возбуждает исключений, и мы можем обработать исключения, как нам удобно.
async def main():
async with aiohttp.ClientSession() as session:
urls = ['https://example.com', 'python://example.com']
tasks = [fetch_status_code(session, url) for url in urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
exceptions = [res for res in results if isinstance(res, Exception)]
successful_results = [res for res in results if not isinstance(res, Exception)]
print(f'Все результаты: {results}')
print(f'Завершились успешно: {successful_results}')
print(f'Завершились с исключением: {exceptions}')
Функция as_completed
Начинает возвращать данные по мере поступления. Однако порядок не определен.
import asyncio
import aiohttp
from aiohttp import ClientSession
from chapter_04 import fetch_status
async def main():
async with aiohttp.ClientSession() as session:
fetchers = [fetch_status(session, 'https://www.example.com', 1),
fetch_status(session, 'https://www.example.com', 1),
fetch_status(session, 'https://www.example.com', 10)]
for finished_task in asyncio.as_completed(fetchers):
print(await finished_task)
asyncio.run(main())
asyncio.as_completed(fetchers, timeout=2) задает тайм-аут. Но созданные задачи продолжают работать в фоновом режиме.
Точный контроль над функциями
Используется wait:
async def main():
async with aiohttp.ClientSession() as session:
fetchers = \
[asyncio.create_task(fetch_status(session, 'https://example.com')),
asyncio.create_task(fetch_status(session, 'https://example.com'))]
done, pending = await asyncio.wait(fetchers)
print(f'Число завершившихся задач: {len(done)}')
print(f'Число ожидающих задач: {len(pending)}')
for done_task in done:
result = await done_task
print(result)Сигнатура wait – список допускающих ожидание объектов, за которым следует факультативный тайм-аут и факультативный
параметр return_when, который может принимать значения ALL_COMPLETED, FIRST_EXCEPTION и FIRST_COMPLETED, а по умолчанию равен ALL_COMPLETED.
wait не возбуждает исключений, исключения содержатся в методе done_task.exception()
Пример обработки исключений
import asyncio
import logging
async def main():
async with aiohttp.ClientSession() as session:
good_request = fetch_status(session, 'https://www.example.com')
bad_request = fetch_status(session, 'python://bad')
fetchers = [asyncio.create_task(good_request),
asyncio.create_task(bad_request)]
done, pending = await asyncio.wait(fetchers)
print(f'Число завершившихся задач: {len(done)}')
print(f'Число ожидающих задач: {len(pending)}')
for done_task in done:
# result = await done_task возбудит исключение
if done_task.exception() is None:
print(done_task.result())
else:
logging.error("При выполнении запроса возникло исключение",
exc_info=done_task.exception())
asyncio.run(main())
Типы future и awaitable
Практически редко применяются, но нужны для понимания
Будущие объекты можно использовать в выражениях await. Это означает «я посплю, пока в будущем объекте не будет установлено значение, с которым я могу работать, а когда оно появится, разбуди меня и дай возможность его обработать».
from asyncio import Future
my_future = Future()
print(f'my_future готов? {my_future.done()}')
my_future.set_result(42)
print(f'my_future готов? {my_future.done()}')
print(f'Какой результат хранится в my_future? {my_future.result()}')
Вариант для использования не до конца определенной переменной:
from asyncio import Future
import asyncio
def make_request() -> Future:
future = Future()
asyncio.create_task(set_future_value(future))
return future
async def set_future_value(future) -> None:
await asyncio.sleep(1)
future.set_result(42)
async def main():
future = make_request()
print(f'Будущий объект готов? {future.done()}')
value = await future
print(f'Будущий объект готов? {future.done()}')
print(value)
asyncio.run(main())
Любой объект, который реализует метод __await__, можно использовать в выражении await. Это объекты, допускающие ожидание (Awaitaible).
Асинхронный контекстный менеджер
Асинхронный контекстный менеджер.
Это класс, реализующий два специальных метода-сопрограммы: __aenter__, который асинхронно захватывает ресурс, и __aexit__, который закрывает ресурс. Сопрограмма __aexit__ принимает несколько аргументов, относящихся к обработке исключений. Пример для сокетов:
import asyncio
import socket
from types import TracebackType
from typing import Optional, Type
class ConnectedSocket:
def __init__(self, server_socket):
self._connection = None
self._server_socket = server_socket
async def __aenter__(self):
print('Вход в контекстный менеджер, ожидание подключения')
loop = asyncio.get_event_loop()
connection, address = await loop.sock_accept(self._server_socket)
self._connection = connection
print('Подключение подтверждено')
return self._connection
async def __aexit__(self,
exc_type: Optional[Type[BaseException]],
exc_val: Optional[BaseException],
exc_tb: Optional[TracebackType]):
print('Выход из контекстного менеджера')
self._connection.close()
print('Подключение закрыто')
async def main():
loop = asyncio.get_event_loop()
server_socket = socket.socket()
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
server_address = ('127.0.0.1', 8000)
server_socket.setblocking(False)
server_socket.bind(server_address)
server_socket.listen()
async with ConnectedSocket(server_socket) as connection:
data = await loop.sock_recv(connection, 1024)
print(data)
asyncio.run(main())
Aiohttp
Сеансовый асинхронный http(s) клиент с автоматической поддержкой cookies. Пул подключений использует один сеанс.
Установка:
pip install aiohttpИспользование:
import asyncio
import aiohttp
from aiohttp import ClientSession
from util import async_timed
async def fetch_status(session: ClientSession, url: str) -> int:
async with session.get(url) as result:
return result.status
async def main():
async with aiohttp.ClientSession() as session:
url = 'https://www.example.com'
status = await fetch_status(session, url)
print(f'Состояние для {url} было равно {status}')
asyncio.run(main())
По умолчанию в сеансе не более 100 подключений. Для увеличения можно создать экземпляр класса TCPConnector, входящего в состав aiohttp, указав максимальное число подключений, и передать его конструктору ClientSession. Подробнее в документации aiohttp.
Тайм-аут:
По умолчанию тайм-аут запроса 5 минут. Можно устанавливать на уровне сеанса или запроса.
import asyncio
import aiohttp
from aiohttp import ClientSession
async def fetch_status(session: ClientSession, url: str) -> int:
ten_millis = aiohttp.ClientTimeout(total=.01)
async with session.get(url, timeout=ten_millis) as result:
return result.status
async def main():
session_timeout = aiohttp.ClientTimeout(total=1, connect=.1)
async with aiohttp.ClientSession(timeout=session_timeout) as session:
await fetch_status(session, 'https://example.com')
asyncio.run(main())
В этом случае полный тайм-аут 1 секунда, для установки соединения - 100мс. В функции fetch_status переопределяется в 10мс.
Множественные запросы
import asyncio
import aiohttp
from aiohttp import ClientSession
from chapter_04 import fetch_status
async def main():
async with aiohttp.ClientSession() as session:
urls = ['https://example.com' for _ in range(1000)]
requests = [fetch_status(session, url) for url in urls]
status_codes = await asyncio.gather(*requests)
print(status_codes)
asyncio.run(main())Обработка ошибок
async def main():
async with aiohttp.ClientSession() as session:
urls = ['https://example.com', 'python://example.com']
tasks = [fetch_status_code(session, url) for url in urls]
results = await asyncio.gather(*tasks, return_exceptions=True)
exceptions = [res for res in results if isinstance(res, Exception)]
successful_results = [res for res in results if not isinstance(res, Exception)]
print(f'Все результаты: {results}')
print(f'Завершились успешно: {successful_results}')
print(f'Завершились с исключением: {exceptions}')
GUI
Tkinter
Встроенный модуль.
Импорт:
import tkinter
from tkinter import *
import tkinter as tkСовременный подход сразу использовать ttk
import tkinter as tk
from tkinter import ttk
root = tk.Tk()
# Используйте ttk.Button, ttk.Entry, ttk.Combobox и т.д.
button = ttk.Button(root, text="Современная кнопка")
button.pack()Иерархия виджетов
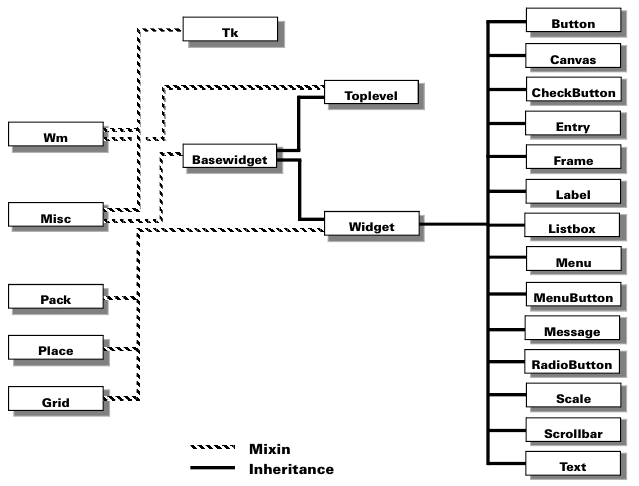
Общая последовательность действий:
- Создать главное окно.
- Создать виджеты и выполнить конфигурацию их свойств (опций).
- Определить события, то есть то, на что будет реагировать программа.
- Описать обработчики событий, то есть то, как будет реагировать программа.
- Расположить виджеты в главном окне.
- Запустить цикл обработки событий.
Создается главное окно от класса Tk модуля tkinter.
root = Tk()Пример окна:
from tkinter import *
root = Tk()
ent = Entry(root,width=20) #поле ввода
but = Button(root, text="Преобразовать") #кнопка
lab = Label(root, width=20, bg='black', fg='white') #метка
def str_to_sort_list(event):
s = ent.get()
lab['text'] = s
but.bind('<Button-1>', str_to_sort_list) #событие левой кнопки мыши
ent.pack() #размещение элементов при помощи менеджера геометрии
but.pack()
lab.pack()
root.mainloop() #основной цикл
Объектно-ориентированный подход
from tkinter import *
class Block:
def __init__(self, master, func):
self.ent = Entry(master, width=20)
self.but = Button(master, text="Преобразовать")
self.lab = Label(master, width=20, bg='black', fg='white')
self.but['command'] = self.str_to_sort
#self.but['command'] = getattr(self, func) #вариант с передачей имени функции
self.ent.pack()
self.but.pack()
self.lab.pack()
def str_to_sort(self):
s = self.ent.get()
self.lab['text'] = s
def str_reverse(self):
s = self.ent.get()
self.lab['text'] = s + '1'
root = Tk()
first_block = Block(root)
#first_block = Block(root, 'str_to_sort')
#second_block = Block(root, 'str_reverse')
root.mainloop()События в этом случае определяются по-другому (через свойство).
Есть стилизация через ttk, типа удобнее, узнать.
Если потом работать с элементами не нужно, то без присвоения переменной
Label(text="Пункт выдачи").pack()Менеджеры геометрии
Три менеджера геометрии – упаковщик (pack), сетка (grid) и размещение по координатам (place). В одном окне (или родительском виджете) нельзя комбинировать разные менеджеры.
Pack
Объекты применяются последовательно, относительно заданной точки в противоположную сторону. Сторона задается параметром side. Окно создается максимальным размером элементов.
По умолчанию side = TOP.
Внутренние (ipadx, ipady) отступы и внешние (padx и pady) отступы.
Изменение размеров окна.
expand (расширение, по умолчанию 0) - равномерное размещение по вертикали.
fill (заполнение) - какое направление экрана заполняем. Может быть NONE, BOTH, X, Y. Без expand не работает.
l1.pack(expand=1, fill=Y)anchor (якорь) – может принимать значения N (north – север), S (south – юг), W (west – запад), E (east – восток) и их комбинации.
Вложения блоков
Для вложения используются классы Frame и LabelFrame (с подписью)
f_top = LabelFrame(text="Верх")
l1 = Label(f_top, width=7, height=4, bg='yellow', text="1")Т е размещаем Frame, затем размещаем элементы.
Виджеты
| Свойство | Назначение | Пример |
| text | Надпись на кнопке | b1['text'] = "Изменено" |
| command | Настройка действия |
b1.config(command=change) self.but['command'] = self.str_to_sort (change - настроенная ранее функция) |
| width и height | Ширина и высота. | По умолчанию ширина и высота текста |
| bg , fg | Цвет фона и текста | b1['bg'] = '#000000' |
| activebackground, activeforeground | Цвет фона и текста во время нажатия | |
| font | Шрифт | b1["font"] = ("Comic Sans MS", 24, "bold") |
Label метка. Похожа на кнопку. Нет опции command, связь с событием с помощью bind.
| Свойство | Назначение | Пример |
| bd | Ширина границы вокруг метки |
Entry, text однострочное и многострочное поле ввода
| Свойство / метод | Назначение | Пример |
| get | Получить текст | s = ent.get() |
| insert(position, text) | Вставить текст. Позиция: 0, END |
e1.insert(0, t.strftime('%H:%M:%S '))
|
| delete | Удалить текст | |
| justify |
Выравнивание строки CENTER - по центру |
Text:
| Свойство / метод | Назначение | Пример |
| wrap |
Правило переноса. WORD - по словам. |
text = Text(width=25, height=5, bg="darkgreen", fg='white', wrap=WORD) |
|
Скролл для текста (и не только для текста) сначала нужно создать |
text = Text(width=20, height=7) text.pack(side=LEFT) scroll = Scrollbar(command=text.yview) scroll.pack(side=LEFT, fill=Y) text.config(yscrollcommand=scroll.set) |
|
| insert |
номер строки и номер столбца Нумерация строк с единицы, а столбцов – с нуля |
text.insert(1.0, s) |
|
Разное форматирование в текстовом поле. |
text.tag_add('title', 1.0, '1.end') text.tag_config('title', justify=CENTER, font=("Verdana", 24, 'bold')) |
Radiobutton радиокнопки, Checkbutton флажки
Listbox списки
| Свойство / метод | Назначение | Пример |
| insert |
Добавить элемент Индекс (0-начало, END-конец) |
for i in ["1", "2"]: lbox.insert(0,i) |
Окно выбора файла
- askopenfilename. Открывает диалоговое окно для выбора файла и возвращает путь к выбранному файлу. Если файл не выбран, возвращается пустая строка.
- askopenfilenames. Открывает диалоговое окно для выбора файлов и возвращает список путей к выбранным файлам.
- askdirectory. Открывает диалоговое окно для выбора каталога (нельзя выбрать несколько каталогов).
- asksaveasfilename. Открывает диалоговое окно для сохранения файла, вместо открытия его.
from tkinter import filedialog
filename = filedialog.askopenfilename() # Открываем диалоговое окно для выбора файла
print(filename)PythonMegaWidgets
Сборник виджетов.
GUI QT6
QT6 + оглавление
Платная лицензия Похоже надо углубиться в лицензирование opensource.
Страницы компонентов
| Label | Push button | Radio button |
| Line edit | Check box | SpinBox |
| QLCD | ComboBox | Slider |
| ListWidget | Table | Calendar |
| ColorDialog | FontDialog | MessageBox |
| Dialogs (save) |
Установка:
pip install pyqt6
pip install pyqt6-toolsМинимальное приложение:
from PyQt6.QtWidgets import QApplication, QWidget
import sys
app = QApplication(sys.argv)
window = QWidget()
window.show()
sys.exit(app.exec())Архитектура QT прячется под стандартную, но это не так. QT основывается на цикле событий, внутри реализованы используемые системные процедуры (таймер, ...), и приходится использовать соответствующие QT-модули, а не системные модули. Поэтому в составе QT много модулей.
| Модуль | Назначение |
| QtWidgets |
Основной и шаблонные виджеты (окно, метка, ...) |
| QtGui |
Классы для интеграции с оконной системой, обработки событий, 2D-графики, базовых изображений, шрифтов, иконок и текста.
QIcon класс работы с иконками |
| QtCore |
Системные модули. |
Типы окон
QMainWindow Главное окно приложения и связанные с ним классы для управления главным окном.
from PyQt6.QtWidgets import QApplication, QMainWindow
import sys
app = QApplication(sys.argv)
window = QMainWindow()
window.statusBar().showMessage("Welcome to pyqt6 coding")
window.show()
sys.exit(app.exec())QMainWindow имеет свой собственный макет, содержащий QToolBars, QDockWidgets, QMenuBar и QStatusBar.
QDialog Базовый класс окна верхнего уровня, используемое для краткосрочных задач и краткого общения с пользователем.
QDialogs может быть модальным или немодальным.
QWidget Базовый класс всех объектов пользовательского интерфейса, получает мышь, клавиатуру и другие события
из оконной системы и отображает свое изображение на экране.
Объектно-ориентированный подход настройки окна
Создаем класс-потомок например от QWidget или QMainWindow, настраиваем свойства и
from PyQt6.QtWidgets import QApplication, QWidget
from PyQt6.QtGui import QIcon
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.setWindowIcon(QIcon('pyqt6lessons\images\python.png'))
self.setStyleSheet('background-color:green')
self.setWindowOpacity(0.5)
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec()) Управление событиями
Основной элемент всех приложений в Qt — класс QApplication. Каждому приложению нужен только один объект QApplication, который содержит цикл событий приложения. Это основной цикл, управляющий всем взаимодействием пользователя с графическим интерфейсом.
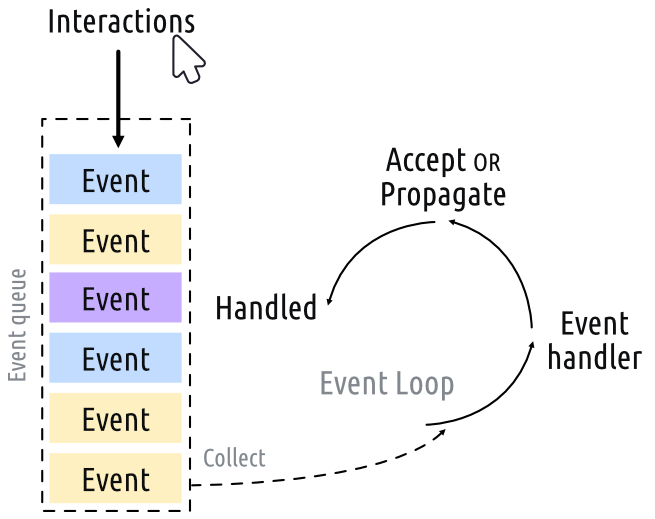
При каждом взаимодействии с приложением генерируется событие, которое помещается в очередь событий. В цикле событий очередь проверяется на каждой итерации: если найдено ожидающее событие, оно вместе с управлением передаётся определённому обработчику этого события. Последний обрабатывает его, затем возвращает управление в цикл событий и ждёт новых событий. Для каждого приложения выполняется только один цикл событий.
Класс QApplication содержит цикл событий Qt (нужен один экземпляр QApplication). Приложение ждёт в цикле событий новое событие, которое будет сгенерировано при выполнении действия. Всегда выполняется только один цикл событий.
Сигналы — уведомления, отправляемые виджетами, когда что-то происходит. Это может быть нажатие кнопки, изменение текста в поле ввода, изменение текста в окне, ... Многие сигналы инициируются в ответ на действия пользователя, но не только: в сигналах могут отправляться данные с дополнительным контекстом произошедшего.
Слоты — приёмники сигналов. Слотом можно сделать любую функцию (или метод), просто подключив к нему сигнал. Принимающая функция получает данные, отправляемые ей в сигнале. У многих виджетов Qt есть встроенные слоты, эти виджеты можно подключать друг к другу напрямую.
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
btn = QPushButton("Click", self)
btn.clicked.connect(self.the_button_was_clicked)
def the_button_was_clicked(self):
print("Clicked")Соединение сигнала и слота происходит в функции btn.clicked.connect(self.the_button_was_clicked) Таблицы событий:
Мышь:
| Тип | Описание |
|---|---|
MouseButtonPress |
Нажата кнопка мыши |
MouseButtonRelease |
Отпущена кнопка мыши |
MouseButtonDblClick |
Двойной клик |
MouseMove |
Движение мыши |
Wheel |
Колёсико мыши |
Enter |
Курсор вошёл в виджет |
Leave |
Курсор покинул виджет |
HoverEnter |
Hover вошёл |
HoverMove |
Hover движение |
HoverLeave |
Hover вышел |
Клавиатура:
| Тип | Описание |
|---|---|
KeyPress |
Нажата клавиша |
KeyRelease |
Отпущена клавиша |
Shortcut |
Сработал shortcut |
ShortcutOverride |
Попытка перехвата shortcut |
InputMethod |
IME ввод |
InputMethodQuery |
Запрос IME |
Фокус и активация
| Тип | Описание |
|---|---|
FocusIn |
Получен фокус |
FocusOut |
Потерян фокус |
ActivationChange |
Изменение активности окна |
Окна и виджеты
| Тип | Описание |
|---|---|
Show |
Виджет показан |
Hide |
Виджет скрыт |
Close |
Закрытие |
Resize |
Изменение размера |
Move |
Перемещение |
Paint |
Перерисовка |
LayoutRequest |
Запрос layout |
UpdateRequest |
Запрос обновления |
Polish |
Финальная инициализация |
PolishRequest |
Запрос polish |
ParentChange |
Изменился родитель |
ParentAboutToChange |
Родитель изменится |
WindowStateChange |
Изменение состояния окна |
WindowActivate |
Окно активировано |
WindowDeactivate |
Окно деактивировано |
WindowTitleChange |
Заголовок окна |
WindowIconChange |
Иконка окна |
WindowBlocked |
Окно заблокировано |
WindowUnblocked |
Окно разблокировано |
Геометрия и экран
| Тип | Описание |
|---|---|
ScreenChangeInternal |
Изменился экран |
ScreenChangeInternal |
DPI/Screen изменился |
OrientationChange |
Смена ориентации |
DevicePixelRatioChange |
Изменение DPR |
Drag & Drop
| Тип | Описание |
|---|---|
DragEnter |
Drag вошёл |
DragMove |
Drag перемещение |
DragLeave |
Drag покинул |
Drop |
Drop |
Буфер обмена
| Тип | Описание |
|---|---|
Clipboard |
Изменился буфер обмена |
Таймеры
| Тип | Описание |
|---|---|
Timer |
Сработал таймер |
ZeroTimerEvent |
Таймер с нулевой задержкой |
Touch / Tablet / Gesture
| Тип | Описание |
|---|---|
TouchBegin |
Touch начало |
TouchUpdate |
Touch обновление |
TouchEnd |
Touch конец |
TabletPress |
Перо нажато |
TabletMove |
Перо движение |
TabletRelease |
Перо отпущено |
Gesture |
Жест |
GestureOverride |
Перехват жеста |
Состояние
| Тип | Описание |
|---|---|
EnabledChange |
Изменение enabled |
FontChange |
Изменение шрифта |
StyleChange |
Изменение стиля |
PaletteChange |
Изменение палитры |
LanguageChange |
Смена языка |
LocaleChange |
Смена локали |
ThemeChange |
Смена темы |
ApplicationStateChange |
Состояние приложения |
Продвинутые опции
| Тип | Описание |
|---|---|
DynamicPropertyChange |
Изменение свойства |
ChildAdded |
Добавлен ребёнок |
ChildRemoved |
Удалён ребёнок |
ChildPolished |
Ребёнок отполирован |
MetaCall |
Вызов meta-object |
ThreadChange |
Смена потока |
DeferredDelete |
Отложенное удаление |
Quit |
Завершение приложения |
PlatformSurface |
Изменение поверхности |
PlatformPanel |
Platform panel |
User |
Начало пользовательских событий |
Пользовательские события
| Тип | Описание |
|---|---|
User |
Базовый пользовательский event |
MaxUser |
Максимальный ID |
event = QEvent(QEvent.Type.User)
QCoreApplication.postEvent(obj, event)Поиск событий:
def event(self, event):
print(event.type())
return super().event(event)
#или
widget.installEventFilter(self)
def eventFilter(self, obj, event):
print(obj, event.type())
return False
QT6Core
QTime класс управления / работы со временем.
time = QTime.currentTime()
text = time.toString('hh:mm')QTimer класс тайминга. Настраивается при инициализации класса.
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.timer = QTimer()
self.timer.timeout.connect(self.update_lcd)
self.timer.start(1000)
self.create_button()
QT6 настройка окна
Компоновщики (Layouts).
Нужны для автоматического упорядочивания и изменения размеров виджетов при изменении размера окна. Без Layouts виджеты имеют фиксированные позиции и размеры. Импортируются все типы компоновщиков через
from PyQt6.QtWidgets import QHBoxLayoutТипы Layouts в Qt Designer
| Vertical Layout (Вертикальный компоновщик) | Располагает виджеты сверху вниз в столбик.
|
| Horizontal Layout (Горизонтальный компоновщик) | Располагает виджеты слева направо в строку.
|
| Grid Layout (Сеточный компоновщик) | Располагает виджеты в таблице (строках и столбцах).
|
| Form Layout (Формовый компоновщик) | Идеален для форм (метка + поле ввода). Располагает виджеты в две колонки: labels слева, поля справа. |
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.mainlayout = QVBoxLayout()
bt1 = QPushButton("one")
bt2 = QPushButton("two")
bt3 = QPushButton("three")
bt4 = QPushButton("four")
self.mainlayout.addWidget(bt1)
self.mainlayout.addWidget(bt2)
self.mainlayout.addWidget(bt3)
self.mainlayout.addWidget(bt4)
self.setLayout(self.mainlayout)
Базовый подход:
- Перетащите виджеты на форму
- Выделите несколько виджетов (зажав Ctrl)
- Нажмите правой кнопкой → "Lay out" → Выберите нужный тип
- Или используйте панель инструментов сверху (кнопки с иконками Layouts)
Вложенные Layouts:
Main Vertical Layout
├── Horizontal Layout (для кнопок)
│ ├── Кнопка "Открыть"
│ ├── Кнопка "Сохранить"
│ └── Кнопка "Выход"
└── Text Edit (занимает оставшееся пространство)Еще класс, просто для примера. Соотношение 1:2
class Window(QWidget):
'''
Вложенные Layout
'''
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.mainlayout = QVBoxLayout()
lbl1 = QLabel("one label")
lbl2 = QLabel("two label")
bt1 = QPushButton("one")
bt2 = QPushButton("two")
self.innerlayout1 = QHBoxLayout()
self.innerlayout1.addWidget(lbl1, stretch=1)
self.innerlayout1.addWidget(bt1,stretch=2)
self.mainlayout.addLayout(self.innerlayout1)
self.innerlayout2 = QHBoxLayout()
self.innerlayout2.addWidget(lbl2, stretch=1)
self.innerlayout2.addWidget(bt2,stretch=2)
self.mainlayout.addLayout(self.innerlayout2)
self.setLayout(self.mainlayout)Растяжения (Stretch):
В коде: layout.addStretch()
В Designer: есть специальный виджет "Horizontal Spacer" / "Vertical Spacer"Выравнивание: В Property Editor настраивается
- layoutStretch — пропорции растяжения
- alignment — выравнивание содержимого
- spacing — расстояние между виджетами, пустое место
self.mainlayout.addSpacing(100)- margin — отступ от краев
Пожелания при использовании Layouts
- Всегда используйте центральный Layout для главного окна
- Не смешивайте абсолютное позиционирование и Layouts
- Тестируйте ресайз окна
- Используйте Spacers для гибких промежутков
- Настройте stretch factors для управления пропорциями
Stretch Factors
Stretch factor — числовое значение, определяющее пропорцию, в которой виджеты делят доступное пространство при растяжении окна.
Базовые принципы:
- По умолчанию stretch factor = 0
- Виджет сохраняет свой минимальный размер
- Не растягивается при увеличении окна
- Чем больше значение, тем больше пространства получает виджет
- Важны относительные пропорции
Настройка при создании
Способ 1: Панель свойств (Property Editor)
- Выберите Layout в иерархии объектов
- Найдите свойство layoutStretch или layoutRowStretch / layoutColumnStretch
- Введите значения через запятую
В данном примере первая кнопка не будет менять размеры, вторая будет занимать 20% от оставшегося свободного места, третья 80%.
Способ 2:Через свойства виджетов внутри Layout
У каждого виджета есть свойство sizePolicy → horizontalStretch / verticalStretch
Способ 3: Через код
# при добавлении нового виджета
self.mainlayout.addWidget(bt1, stretch=1)
self.mainlayout.addWidget(bt2, stretch=3)
self.mainlayout.addWidget(bt3, stretch=0)
self.mainlayout.addWidget(bt4, stretch=5)Настройка после создания
Способ 1: Использовать setStretch(index, stretch)
# Предположим, у вас уже есть Layout с виджетами
self.mainlayout.addWidget(bt1, stretch=1)
self.mainlayout.addWidget(bt2, stretch=3)
self.mainlayout.addWidget(bt3, stretch=0)
self.mainlayout.addWidget(bt4, stretch=5)
# Позже меняем stretch для bt4 (индекс 3, так как индексы начинаются с 0)
self.mainlayout.setStretch(3, 2) # Меняем с 5 на 2Способ 2: Получить индекс виджета динамически
# Находим индекс виджета bt4 в Layout
index = self.mainlayout.indexOf(bt4)
if index != -1: # -1 означает "не найден"
self.mainlayout.setStretch(index, 2)Способ 3: Пересоздать Layout (более кардинальный)
# Удаляем все виджеты из Layout
while self.mainlayout.count():
item = self.mainlayout.takeAt(0)
if item.widget():
item.widget().hide()
# Добавляем заново с новыми stretch factors
self.mainlayout.addWidget(bt1, stretch=1)
self.mainlayout.addWidget(bt2, stretch=3)
self.mainlayout.addWidget(bt3, stretch=0)
self.mainlayout.addWidget(bt4, stretch=2) # Новое значение!Способ 4: Изменить через setSizePolicy виджета.
# Получаем текущую политику размеров
policy = bt4.sizePolicy()
# Устанавливаем горизонтальный/вертикальный stretch
policy.setHorizontalStretch(2) # Для Horizontal Layout
policy.setVerticalStretch(2) # Для Vertical Layout
bt4.setSizePolicy(policy)
bt4.update() # Обновляем виджетВажно: Этот метод влияет на поведение виджета во всех Layout, где он находится!
Способ 5: Временное отключение обновления для избежания мерцания при изменении:
# Блокируем обновление
self.setUpdatesEnabled(False)
# Меняем stretch
index = self.mainlayout.indexOf(bt4)
self.mainlayout.setStretch(index, 2)
# Включаем обновление и форсируем перерасчет
self.setUpdatesEnabled(True)
self.mainlayout.invalidate() # Помечаем Layout как невалидный
self.mainlayout.activate() # Принудительно пересчитываемОсобенности работы:
- Изменения применяются немедленно — Layout пересчитается при следующем обновлении интерфейса
- Индексы начинаются с 0 и соответствуют порядку добавления
- Spacer'ы тоже имеют индексы — учитывайте это при поиске
- setStretch() работает только для QBoxLayout (QVBoxLayout, QHBoxLayout)
- Для QGridLayout используйте setRowStretch() и setColumnStretch()
- Для QFormLayout сложнее — лучше удалить и добавить заново
Проверка текущих значений:
# Получить текущий stretch factor
current_stretch = self.mainlayout.stretch(3) # Для индекса 3
print(f"Текущий stretch: {current_stretch}")
# Получить список всех stretch factors
for i in range(self.mainlayout.count()):
widget = self.mainlayout.itemAt(i).widget()
stretch = self.mainlayout.stretch(i)
if widget:
print(f"Индекс {i}: {widget.text()} - stretch={stretch}")
Класс окна
Для управления классом окна, класс создается, затем настраиваются нужные свойства
from PyQt6.QtWidgets import QApplication, QWidget
from PyQt6.QtGui import QIcon
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())Свойства:
self.setWindowIcon(QIcon('pyqt6lessons\images\python.png'))
self.setStyleSheet('background-color:green')
self.setWindowOpacity(0.5)
| Свойство | Применение |
| Размеры окна |
self.setGeometry(x,y, height, width) self.setGeometry(200,200, 700, 400) |
| Заголовок окна | self.setWindowTitle("Python GUI Development") |
QT6 desiner
Устанавливается при установке pyqt6-tools
У меня вызвался обычной командой
(myenv) D:\projects\calclulator_long>pyside6-designer.exeТипы создаваемых окон:
- 3 типа диалоговых окон,
- Основное окно
- 10 виджетов.
Различаются родительским классом и наличием дополнительных виджетов (кнопки, ...)
Предпросмотр результата
Блок меню Form - Preview... очень занимательный.
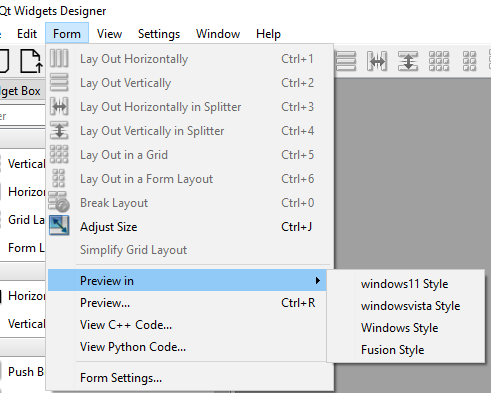
QT использует стили операционных систем, поэтому вид будет отличаться на разных ОС.
Слои (Layouts)
Настраивается отдельно тип для всей формы и для группы элементов.
Настройка для группы элементов: выделяются виджеты, ПКМ - Lay Out - Нужный тип.
Для всей формы: ПКМ на пустом месте формы - Lay Out - Нужный тип.
Использование .ui файла
Использование в скрипте
Два варианта: преобразование в py файл и загрузка в py скрипт ui-файла во время выполнения.
Преобразование в python файл:
(myenv) D:\projects\calclulator_long>pyuic6 -x testui.ui -o testuicreated.pyПосле этого запуск *,py файла откроет пользовательский интерфейс. При изменении *.ui файла необходимо обновить файл исходного кода и связанных процедур.
Загрузка ui файла во время выполнения
from PyQt6.QtWidgets import QApplication, QWidget
import sys
from PyQt6 import uic
class UI(QWidget):
def __init__(self):
super().__init__()
uic.loadUi("WindowUI.ui", self)
app = QApplication(sys.argv)
window = UI()
window.show()
app.exec()Доступ к виджетам внутри .ui файла
Для дальнейшего доступа к виджетам из py скрипта необходимо знать тип виджета и имя объекта. Например, есть виджет типа QLineEdit, имя объекта lineEdit_price.
Создадим свойство объекта через FindChild
class UI(QWidget):
def __init__(self):
super().__init__()
uic.loadUi("double_spin.ui", self)
self.linePrice = self.findChild(QLineEdit, "lineEdit_price")Дальше с этим свойством работать также как с созданным объектом. Пример:
lass UI(QWidget):
def __init__(self):
super().__init__()
uic.loadUi("double_spin.ui", self)
self.linePrice = self.findChild(QLineEdit, "lineEdit_price")
self.doublespin = self.findChild(QDoubleSpinBox, "doubleSpinBox")
self.doublespin.valueChanged.connect(self.spin_selected)
self.lineresult = self.findChild(QLineEdit, "lineEdit_total")
def spin_selected(self):
if self.linePrice.text() != 0:
price = int(self.linePrice.text())
totalPrice = self.doublespin.value() * price
self.lineresult.setText(str(totalPrice))Соединение действий виджетов
Функционал урезан. Нажать кнопку Edit signals/slots
При наведении мыши виджет становится красным. Если нажать виджет, с которого сигнал будет исходить и, удерживая мышь, переместить указатель на виджет, на который будет влиять сигнал, появится стрелка и элемент выбора сигналов/слотов.
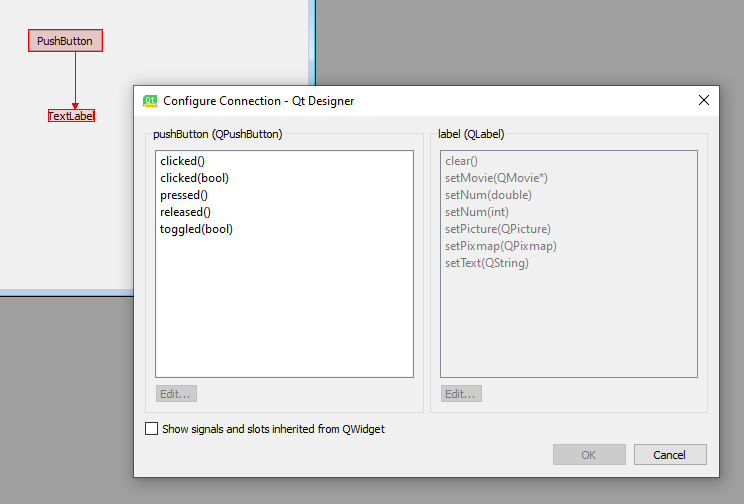
Нужно установить флажок внизу. Выбирается сигнал, слот и все работает даже на превью.
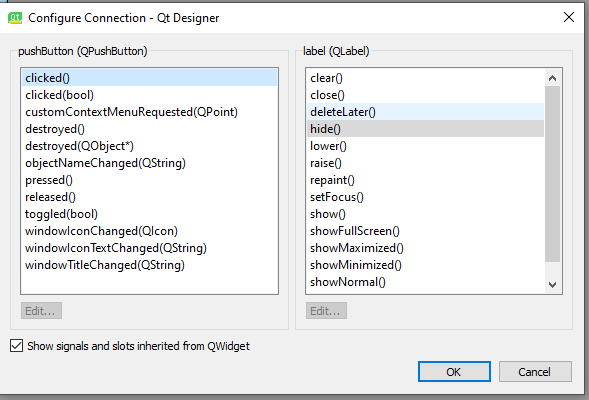
QT6 QLabel, LCD
QLabel
Класс QLabel используется для отображения сообщений и изображений,
- Импорт QLabel
- Создание объекта класса QLabel
- Применение методов класса к переменной
from PyQt6.QtWidgets import QApplication, QWidget, QLabel
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
label = QLabel("", self)
label.setText('first text in label')
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())Для создания метки с изображением текст не передается
label = QLabel(self)Таблица методов:
| Метод | Назначение |
| setText() | Устанавливается новый текст метки |
| setNum() | добавляет целое или двойное значение |
| clear() | удаляет текст |
| setMovie() |
установки изображения gif movie = QMovie('images/sky.gif') |
| setFont() | Изменения шрифта, setFont() ожидает класс QFont, (потомок QtGui) label.setFont(QFont("Sanserif", 15)) |
| label.setStyleSheet() |
Изменение цвета шрифта label.setStyleSheet('color:red') |
| Добавление изображения |
|
| setPixamp() | pixmap = QPixmap('images/python.png') label.setPixmap(pixmap) |
| QImage, QBitmap QPicture |
QLCDNumber
Класс для отображения 7-сегментного дисплея, отображает 5 (пять) 8- 10- 16- ричных элементов.
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.timer = QTimer()
self.timer.timeout.connect(self.update_lcd)
self.timer.start(1000)
self.create_button()
def create_button(self):
vbox = QVBoxLayout()
self.lcd = QLCDNumber()
self.lcd.setStyleSheet('background:red')
vbox.addWidget(self.lcd)
time = QTime.currentTime()
text = time.toString('hh:mm')
self.lcd.display(text)
self.setLayout(vbox)
def update_lcd(self):
time = QTime.currentTime()
text = time.toString('hh:mm')
self.lcd.display(text)
QT6 Buttons
Командная кнопка является наиболее часто используемым виджетом в любом графическом интерфейсе пользователя. Нажатие (click) кнопки является командой компьютеру выполнить какое-либо действие. Типичными кнопками являются "ОК", "Применить", "Отмена", "Закрыть"., Да, Нет и Справка.
Командная кнопка имеет прямоугольную форму и обычно отображает текстовую метку, описывающую ее действие. Можно указать комбинацию клавиш, указав перед нужным символом амперсанд в тексте.
чтобы отобразить кнопку в приложении, вам необходимо создать экземпляр класса QPushButton.
from PyQt6.QtWidgets import QApplication, QWidget, QPushButton
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
btn = QPushButton("Click", self)
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())Методы класса:
| Метод | Описание |
| setText() | Изменение текста |
| setIcon() |
Добавление иконки на кнопку btn.setIcon(QIcon("images/python.png")) |
|
Изменение размера иконки
|
|
| setGeometry() | Настройка положения кнопки, |
| setMenu() |
Всплывающее меню над кнопкой. Сначала создать объект QMenu, класс QMenu связан с модулем QtWidgets, класс QMenu предоставляет виджет меню для использования в строках меню, контекстных меню и других всплывающих меню. |
| setFont() |
Настройка шрифта btn.setFont(QFont("Times", 14, QFont.Weight.ExtraBold)) |
| setCheckable() |
Вид кнопки при нажатии меняется. Выделяется и снимается выделение. |
Кнопка, которую можно включить (установить флажок) или выключить (снять флажок). Переключатели обычно предоставляют
пользователю возможность выбора "из многих". В группе переключателей одновременно может быть установлен только один переключатель, если пользователь выбирает другую кнопку, ранее выбранная кнопка отключается. Существуют различные методы, которые вы можете использовать, например, у нас есть IsChecked(), и он возвращает логическое значение true, если кнопка находится в выбранном состоянии, или у нас есть метод setIcon(), с помощью которого мы можем добавить значок для радиокнопки, а также setText(), который задает текст выбранной кнопки. Также существуют различные сигналы, которые вы можете использовать, например, у нас есть переключаемый сигнал, который используется всякий раз, когда переключатель меняет свое состояние с установленного на снятое и наоборот.
from PyQt6.QtWidgets import QApplication, QWidget, QHBoxLayout, QRadioButton, QLabel
from PyQt6.QtWidgets import QVBoxLayout
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
hbox = QHBoxLayout()
self.label = QLabel("", self)
vbox = QVBoxLayout()
vbox.addWidget(self.label)
vbox.addLayout(hbox)
rad1 = QRadioButton("Python")
rad1.toggled.connect(self.radio_selected)
hbox.addWidget(rad1)
rad2 = QRadioButton("Java")
rad2.toggled.connect(self.radio_selected)
hbox.addWidget(rad2)
rad3 = QRadioButton("JavaScript")
rad3.toggled.connect(self.radio_selected)
hbox.addWidget(rad3)
self.setLayout(vbox)
def radio_selected(self):
radio_btn = self.sender()
if radio_btn.isChecked():
self.label.setText(f'Selected: {radio_btn.text()}')
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())Методы класса:
| Метод | Описание |
| isChecked() | Возвращает True если кнопка выбрана |
| setChecked() | Переводит кнопку в выбранное состояние |
| setIcon() | Устанавливает иконку кнопки |
| setText() | Текст |
QT6 QLineEdit
Виджет позволяет вводить и редактировать одну строку обычного текста с помощью полезного набора функций редактирования, включая отмену и повтор, вырезание и вставку, а также перетаскивание.
Методы:
| Метод | Назначение |
| setEchoMode() |
Режим эхо. Варианты:
|
| setFont() | Настройка шрифта |
| maxLength() | Максимальная длина текста |
| setText() | Устанавливает текст |
| text() | Получает текст |
| clear() | Очищает строку ввода |
| setReadOnly() | Установка режима только для чтения |
| setEnabled() | Доступность компонента пользователю |
| setFocus() | Установить фокус |
| setPlaceholderText() | Текст когда поле пустое |
QT6 CheckBox, SpinBox, ComboBox
QCheckbox
Это кнопка выбора, которую можно включить (установить флажок) или выключить (снять флажок). Флажки обычно используются для обозначения функций в приложении, которые можно включать или отключать, не затрагивая другие. При изменении состояния флажка выдается сигнал StateChanged(). Метод IsChecked() используется для запроса, установлен ли флажок.
Методы:
| Метод | Описание |
| isChecked() | |
| setIcon() | |
| setText() | |
| setChecked() |
Сигналы:
stateChanged
QSpinbox
QSpinBox предназначен для обработки целых чисел и дискретных наборов значений, позволяет выбирать значение, нажимая кнопки вверх / вниз или нажимая клавиши вверх / вниз на клавиатуре, чтобы увеличить / уменьшить отображаемое в данный момент значение. Также возможно ввести значение вручную.
Методы:
| Метод | Описание |
| value() | текущее выбранное целое значение |
| text() | отображения текста в окне прокрутки |
|
setMinimum() |
|
| setMaximum() | |
| setPrefix() | текстовый префикс, добавляемый перед значением, возвращаемым полем прокрутки. |
| setSuffix() | текст суффикса, добавляемый к значению, возвращаемому блоком spin. |
Сигналы:
valueChanged()
editingFinished() выдается при потере фокуса на spinbox. Предполагаю, актуально для приложений с web backend при передаче финальных данных.
from PyQt6.QtWidgets import QApplication, QWidget, QLabel, QHBoxLayout, QLineEdit
from PyQt6.QtWidgets import QSpinBox
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
hbox = QHBoxLayout()
label = QLabel("Laptop price: ")
self.lineedit = QLineEdit()
self.spinbox = QSpinBox()
self.spinbox.valueChanged.connect(self.spin_selected)
self.total_result = QLineEdit()
hbox.addWidget(label)
hbox.addWidget(self.lineedit)
hbox.addWidget(self.spinbox)
hbox.addWidget(self.total_result)
self.setLayout(hbox)
def spin_selected(self):
if self.lineedit.text() != 0:
price = int(self.lineedit.text())
totalPrice = self.spinbox.value() * price
self.total_result.setText(str(totalPrice))
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())QComboBox
Виджет выбора, отображающий текущий элемент. Также отображает список выбираемых элементов. Может быть редактируемым.
Также есть специализированный ComboBox: для выбора шрифтов (fontComboBox).
Методы:
| Метод | Описание |
| setItemText() | Устанавливает или изменяет текст элемента в поле со списком. |
| removeItem() | Удаляет определенный элемент из поля со списком. |
| clear() | Удаляет все элементы из поля со списком. |
| currentText() | Возвращает текст текущего элемента, то есть элемента, который выбран в данный момент. |
| setCurrentIndex() | Устанавливает текущий индекс поля со списком, то есть задает желаемый элемент в поле со списком в качестве выбранного в данный момент элемента. |
| count() | Возвращает количество элементов в поле со списком. |
| setEditable() | Сделайте поле со списком доступным для редактирования, то есть пользователь можно редактировать элементы в поле со списком. |
| addItem() | Добавляет указанное содержимое в поле со списком. |
| itemText() | Возвращает текст в указанное расположение индекса в поле со списком. |
| currentIndex() | Возвращает индексное местоположение текущего выбранного элемента в поле со списком. Если поле со списком пусто или в поле со списком в данный момент не выбран ни один элемент, метод вернет значение -1 в качестве индекса. |
Сигналы
currentIndexChanged() выбор нового элемента
editTextChanged() изменение текста в редактируемом комбобоксе
from PyQt6.QtWidgets import QApplication, QWidget, QComboBox, QLabel, QHBoxLayout, QVBoxLayout
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
hbox = QHBoxLayout()
label = QLabel('Select type: ')
self.combo = QComboBox()
self.combo.addItem('')
self.combo.addItem('Current account')
self.combo.addItem('Deposite account')
self.combo.addItem('Saving account')
self.combo.currentTextChanged.connect(self.updresult)
hbox.addWidget(label)
hbox.addWidget(self.combo)
vbox = QVBoxLayout()
vbox.addLayout(hbox)
self.label_result = QLabel('')
vbox.addWidget(self.label_result)
self.setLayout(vbox)
def updresult(self):
self.label_result.setText('Your type: ' + self.combo.currentText())
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())QT6 QSlider, QListWidget
QSlider
Ползунок - виджет управления ограниченным значением. Позволяет перемещать ручку ползунка и преобразовывать положение ручки в целое значение в допустимом диапазоне.
Слайдер бывает горизонтальным и вертикальным
self.slider.setOrientation(Qt.Orientation.Horizontal)Настройка положения галочки ползунка
self.slider.setTickPosition(QSlider.TickPosition.TicksAbove)Интервал шага
self.slider.setTickInterval(5)Границы диапазона
self.slider.setMinimum(0)
self.slider.setMaximum(100) Методы
| Метод | Назначение |
| minimum() | возвращает минимальное значение ползунка |
| maximum() | возвращает максимальное значение ползунка |
| setValue() | используется для установки значения ползунка |
Сигналы
| Сигнал | Назначение |
| valueChanged() | подается при перемещении ручки ползунка |
| sliderPressed() | подается, когда пользователь начинает перетаскивать ручку ползунка. |
| sliderMoved() | подается, когда пользователь перемещает ручку ползунка. |
| sliderReleased() | подается, когда пользователь отпускает ручку ползунка |
QListWidget
QListWidget - представление списка, аналогичное QListView, но с классическим интерфейсом на основе элементов для добавления и удаления элементов. QListWidget использует внутреннюю модель для управления удалением элементов. QListWidget использует внутреннюю модель для управления каждым QListWidgetItem в списке.
Методы
| Метод | Назначение |
| insertItem() | вставляет новый элемент в виджет списка в указанном месте. |
| insertItems() | вставляет несколько элементов из предоставленного списка, начиная с указанного места |
| count() | возвращает количество элементов в списке. |
| takeItem() | удаляет и возвращает элементы из указанной строки |
| CurrentItem() | возвращает текущий элемент в списке |
| addItem() | добавляет элемент с указанным текстом в конец |
| currentRow() | возвращает номер строки выбранного элемента. Если ни один элемент не выбран, возвращает -1 |
Сигналы
| Сигнал | Назначение |
| clicked() | подается при щелчке по элементу в виджете списка |
| currentRowChanged() | подается при изменении строки текущего элемента списка |
| currentTextChanged() | подается при каждом изменении текста в текущем элементе списка |
| currentItemChanged() | подается при изменении фокуса текущего элемента списка |
QT6 QTable, QMessageBox, Dialogs
QTable
Отображение таблиц. Элементы в QTableWidget предоставляются с помощью QTableWidgetItem.
Методы:
| Метод | Назначение |
| setRowCount() | определения количества строк |
| setColumnCount() | определения количества столбцов |
| rowCount() | возвращает количество строк |
| columnCount() | возвращает количество столбцов |
from PyQt6.QtWidgets import QApplication, QWidget, QTableWidget, QTableWidgetItem, QVBoxLayout
import sys
class Window(QWidget):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
self.create_button()
def create_button(self):
vbox = QVBoxLayout()
curtable = QTableWidget()
curtable.setRowCount(3)
curtable.setColumnCount(3)
curtable.setItem(0, 0, QTableWidgetItem('Заголовок столбца 1'))
curtable.setItem(0, 1, QTableWidgetItem('Заголовок столбца 2'))
curtable.setItem(0, 2, QTableWidgetItem('Заголовок столбца 3'))
vbox.addWidget(curtable)
self.setLayout(vbox)
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())QMessageBox
QMessageBox - модальный диалог информирования пользователя и получения ответа. В окне сообщения отображается текст, есть необязательный подробный текст в случае необходимости. Также может отображаться значок и стандартные кнопки для принятия ответа пользователя. Существуют различные типы диалогов (about messagebox, information messagebox, warning messagebox, multichoice messagebox).
from PyQt6.QtWidgets import QApplication, QDialog, QPushButton
from PyQt6.QtWidgets import QMessageBox
from PyQt6 import uic
import sys
class Window(QDialog):
def __init__(self):
super().__init__()
self.setGeometry(200,200, 700, 400)
self.setWindowTitle("Python GUI Development")
uic.loadUi("messagedemo.ui", self)
self.loadguiobjects()
def loadguiobjects(self):
self.butt_warn = self.findChild(QPushButton, "pushButton_warn")
self.butt_warn.clicked.connect(self.show_warn)
self.butt_info = self.findChild(QPushButton, "pushButton_info")
self.butt_info.clicked.connect(self.show_info)
self.butt_abt = self.findChild(QPushButton, "pushButton_abt")
self.butt_abt.clicked.connect(self.show_about)
def show_warn(self):
QMessageBox.warning(self, 'Warning', 'This is a warning message')
def show_info(self):
#кастомный messagebox + стандартные кнопки
msg_box = QMessageBox(self)
msg_box.setWindowTitle('Information')
msg_box.setText('This is a information message')
msg_box.setIcon(QMessageBox.Icon.Information)
# Добавляем кнопки
ok_button = msg_box.addButton('OK', QMessageBox.ButtonRole.AcceptRole)
cancel_button = msg_box.addButton('Отменить задание', QMessageBox.ButtonRole.RejectRole)
# Показываем сообщение и ждем нажатия кнопки
msg_box.exec()
# Проверяем какая кнопка была нажата
if msg_box.clickedButton() == cancel_button:
print("Действие отменено")
elif msg_box.clickedButton() == ok_button:
print("OK нажата")
def show_about(self):
# другой способ с разными кнопкам
msg_box = QMessageBox(
QMessageBox.Icon.NoIcon,
'About',
'This is a about message',
QMessageBox.StandardButton.Ok | QMessageBox.StandardButton.Cancel
)
# Изменяем текст стандартных кнопок
msg_box.button(QMessageBox.StandardButton.Ok).setText('Продолжить')
msg_box.button(QMessageBox.StandardButton.Cancel).setText('Отменить задание')
result = msg_box.exec()
if result == QMessageBox.StandardButton.Ok:
print("Продолжаем выполнение")
else:
print("Задание отменено")
app = QApplication(sys.argv)
window = Window()
window.show()
sys.exit(app.exec())SaveFile
Сама кнопка меню в сформированном из QtDesiner, класс Ui_MainWindow
from PyQt6.QtWidgets import QMainWindow, QApplication, QFileDialog, QMessageBox
import sys
from notepadapp import Ui_MainWindow
class NotePadWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super().__init__()
self.setupUi(self)
self.show()
self.actionSave.triggered.connect(self.save_file)
def save_file(self):
filename = QFileDialog.getSaveFileName(self, 'Save file')
if filename[0]:
f = open(filename[0], 'w')
with f:
text = self.textEdit.toPlainText()
f.write(text)
QMessageBox.about(self, 'Save file', 'File saved successfully!')
app = QApplication(sys.argv)
Note = NotePadWindow()
sys.exit(app.exec())
Пример: notepad
Начальная информация
Внешний вид приложения:
Элементы интерфейса: меню, быстрые кнопки и многострочное поле ввода. Элементы меню:
|
|
|
|
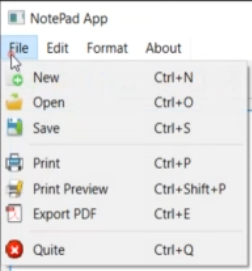
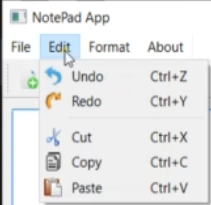
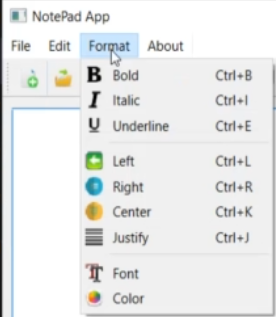
Установленные модули:
pip install pyqt6Параметры интерфейса:
Окно - MainWindow
from PyQt6.QtWidgets import QMainWindow, QApplication, QFileDialog, QMessageBox
from PyQt6.QtPrintSupport import QPrinter, QPrintDialog, QPrintPreviewDialog
from PyQt6.QtCore import QFileInfo
from PyQt6.QtGui import QFont
import sys
from notepadapp import Ui_MainWindow
class NotePadWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super().__init__()
self.setupUi(self)
self.show()
self.actionSave.triggered.connect(self.file_save)
self.actionNew.triggered.connect(self.file_new)
self.actionOpen.triggered.connect(self.file_open)
self.actionPrint.triggered.connect(self.file_print)
self.actionPrint_preview.triggered.connect(self.preview_dialog)
self.actionExport_PDF.triggered.connect(self.exporting_pdf)
self.actionQuit.triggered.connect(self.exit_app)
self.actionUndo.triggered.connect(self.textEdit.undo)
self.actionRedo.triggered.connect(self.textEdit.redo)
self.actionCut.triggered.connect(self.textEdit.cut)
self.actionCopy.triggered.connect(self.textEdit.copy)
self.actionPaste.triggered.connect(self.textEdit.paste)
self.actionBold.triggered.connect(self.text_bold)
def maybe_save(self) -> bool:
if not self.textEdit.document().isModified():
return True
ret = QMessageBox.warning(self, "Application",
"The document changed \n Save working?",
QMessageBox.StandardButton.Save |
QMessageBox.StandardButton.Discard |
QMessageBox.StandardButton.Cancel)
if ret == QMessageBox.StandardButton.Save:
self.file_save()
return True
elif ret == QMessageBox.StandardButton.Cancel:
return False
return True
def file_new(self):
if self.maybe_save():
self.textEdit.clear()
def file_save(self):
filename = QFileDialog.getSaveFileName(self, 'Save file')
if filename[0]:
f = open(filename[0], 'w')
with f:
text = self.textEdit.toPlainText()
f.write(text)
QMessageBox.about(self, 'Save file', 'File saved successfully!')
def file_open(self):
self.maybe_save()
filename = QFileDialog.getOpenFileName(self, 'Open file')
if filename[0]:
f = open(filename[0], 'r')
with f:
data = f.read()
self.textEdit.setText(data)
def file_print(self):
printer = QPrinter(QPrinter.PrinterMode.HighResolution)
dialog = QPrintDialog(printer)
if dialog.exec() == QPrintDialog.DialogCode.Accepted:
self.textEdit.print(printer)
def print_preview(self, printer):
self.textEdit.print(printer)
def preview_dialog(self):
printer = QPrinter(QPrinter.PrinterMode.HighResolution)
preview_dialog = QPrintPreviewDialog(printer, self)
preview_dialog.paintRequested.connect(self.print_preview)
preview_dialog.exec()
def exporting_pdf(self):
#fn, _ = QFileDialog.getSaveFileName(self, 'Export PDF', "PDF Files (.pdf) ;; AllFiles()")
fn, _ = QFileDialog.getSaveFileName(self, 'Export PDF','',"PDF Files (.pdf) ;; All Files (*)")
if QFileInfo(fn).suffix() == "":
fn += '.pdf'
printer = QPrinter(QPrinter.PrinterMode.HighResolution)
printer.setOutputFormat(QPrinter.OutputFormat.PdfFormat)
printer.setOutputFileName(fn)
self.textEdit.document().print(printer)
def exit_app(self):
self.close()
def text_bold(self):
font = QFont()
font.setBold(True)
self.textEdit.setFont(font)
app = QApplication(sys.argv)
Note = NotePadWindow()
sys.exit(app.exec())Это неполный код, операции однотипные.
QT6: База данных
Пример для работы с Mysql
pip install mysql-connector-pythonПример кода для подключения к базе и создания БД:
from PyQt6 import QtCore, QtGui, QtWidgets
import mysql.connector as mc
class Ui_Form(object):
def setupUi(self, Form):
Form.setObjectName("Form")
Form.resize(456, 300)
self.verticalLayout = QtWidgets.QVBoxLayout(Form)
self.verticalLayout.setObjectName("verticalLayout")
self.horizontalLayout = QtWidgets.QHBoxLayout()
self.horizontalLayout.setObjectName("horizontalLayout")
self.label_dbname = QtWidgets.QLabel(parent=Form)
font = QtGui.QFont()
font.setPointSize(14)
self.label_dbname.setFont(font)
self.label_dbname.setObjectName("label_dbname")
self.horizontalLayout.addWidget(self.label_dbname)
self.lineEdit_dbname = QtWidgets.QLineEdit(parent=Form)
font = QtGui.QFont()
font.setPointSize(14)
self.lineEdit_dbname.setFont(font)
self.lineEdit_dbname.setText("")
self.lineEdit_dbname.setObjectName("lineEdit_dbname")
self.horizontalLayout.addWidget(self.lineEdit_dbname)
self.verticalLayout.addLayout(self.horizontalLayout)
spacerItem = QtWidgets.QSpacerItem(20, 40, QtWidgets.QSizePolicy.Policy.Minimum, QtWidgets.QSizePolicy.Policy.Expanding)
self.verticalLayout.addItem(spacerItem)
self.horizontalLayout_2 = QtWidgets.QHBoxLayout()
self.horizontalLayout_2.setObjectName("horizontalLayout_2")
self.pushButton_dbcreate = QtWidgets.QPushButton(parent=Form)
self.pushButton_dbcreate.setObjectName("pushButton_dbcreate")
self.pushButton_dbcreate.clicked.connect(self.create_db)
self.horizontalLayout_2.addWidget(self.pushButton_dbcreate)
self.pushButton_dbconn = QtWidgets.QPushButton(parent=Form)
self.pushButton_dbconn.setObjectName("pushButton_dbconn")
self.pushButton_dbconn.clicked.connect(self.check_connect)
self.horizontalLayout_2.addWidget(self.pushButton_dbconn)
self.verticalLayout.addLayout(self.horizontalLayout_2)
self.label_result = QtWidgets.QLabel(parent=Form)
font = QtGui.QFont()
font.setFamily("PMingLiU-ExtB")
font.setPointSize(14)
self.label_result.setFont(font)
self.label_result.setText("")
self.label_result.setObjectName("label_result")
self.verticalLayout.addWidget(self.label_result)
self.retranslateUi(Form)
QtCore.QMetaObject.connectSlotsByName(Form)
def create_db(self):
try:
mydb = mc.connect(
host="192.168.1.193",
user="root",
password="rootpassword"
)
cursor = mydb.cursor()
dbname = self.lineEdit_dbname.text()
cursor.execute("CREATE DATABASE {} ".format(dbname))
self.label_result.setText('Database {} created!'.format(dbname))
except mc.Error as e:
self.label_result.setText(str(e))
def check_connect(self):
try:
mydb = mc.connect(
host="192.168.1.193",
user="root",
password="rootpassword",
database="pyqtdb"
)
self.label_result.setText("Connected!")
except mc.Error as e:
self.label_result.setText(str(e))
def retranslateUi(self, Form):
_translate = QtCore.QCoreApplication.translate
Form.setWindowTitle(_translate("Form", "Form"))
self.label_dbname.setText(_translate("Form", "Database name:"))
self.pushButton_dbcreate.setText(_translate("Form", "Create Database"))
self.pushButton_dbconn.setText(_translate("Form", "Database connection"))
if __name__ == "__main__":
import sys
app = QtWidgets.QApplication(sys.argv)
Form = QtWidgets.QWidget()
ui = Ui_Form()
ui.setupUi(Form)
Form.show()
sys.exit(app.exec())
Авторизация
Авторизация через ВК
Перейти на VK для разработчиков
Создать новое приложение, страницы настроек:
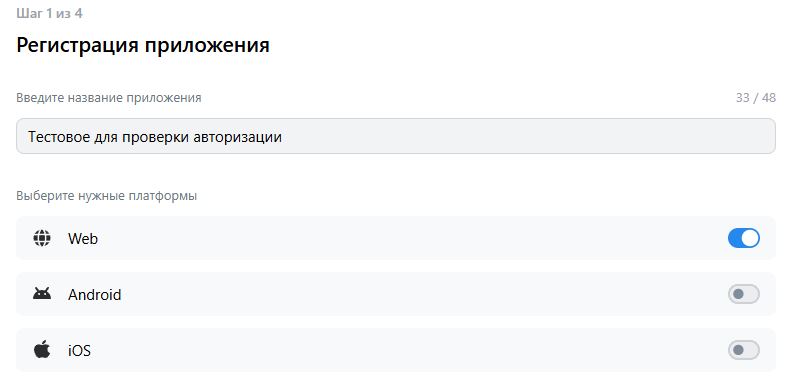
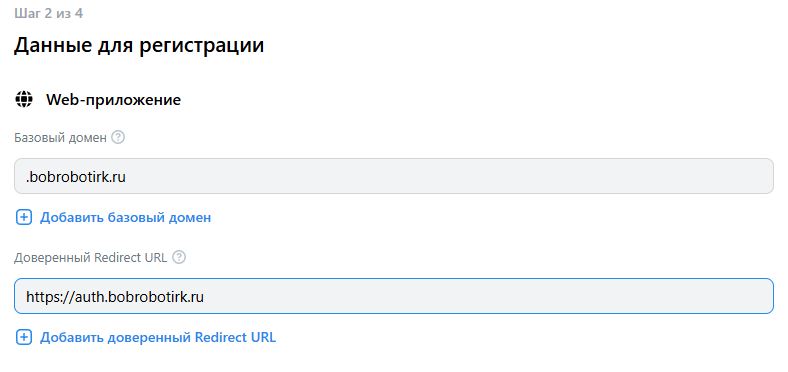
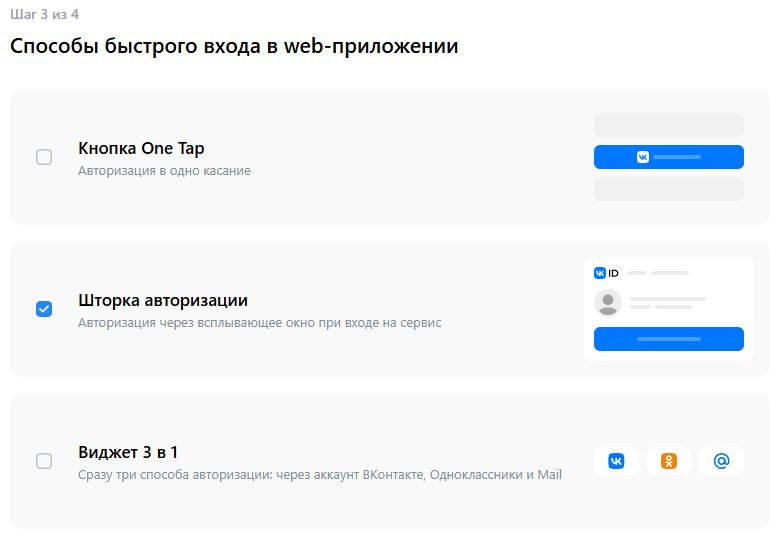 В настройках приложения будут защищенный ключ и сервисный ключ.
В настройках приложения будут защищенный ключ и сервисный ключ.
RBAC+ACL модель
Это гибридная модель, где: пользователь имеет общую роль доступа (например, can_manage_company или viewer_of_sphere) и у этой роли есть контекст, т.е. привязка к объекту: компании или сфере
Таблицы
SQL запросы для PostgreSQL
Пользователи:
CREATE TABLE users (
user_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
username TEXT UNIQUE NOT NULL,
fio TEXT NOT NULL DEFAULT '',
phone TEXT NOT NULL,
password_hash TEXT NOT NULL
);Роли:
CREATE TABLE roles (
role_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
role_name TEXT NOT NULL UNIQUE,
role_description TEXT
);Сферы:
CREATE TABLE fields (
field_id INTEGER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
field_name TEXT NOT NULL
);Компании:
CREATE TABLE companies (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
field_id INTEGER REFERENCES fields(id)
);Связь между всеми параметрами
CREATE TABLE user_role_assignments (
user_id INTEGER REFERENCES users(id),
role_id INTEGER REFERENCES roles(id),
field_id INTEGER REFERENCES fields(id), -- либо это...
company_id INTEGER REFERENCES companies(id), -- ...либо это
PRIMARY KEY (user_id, role_id, field_id, company_id),
CHECK (
(field_id IS NOT NULL AND company_id IS NULL) OR
(field_id IS NULL AND company_id IS NOT NULL)
)
);Тестирование
Locust Введение
Locust - open-source python framework для проведения нагрузочного тестирования. Поддерживает распределенные серверы. Используется для тестирования web серверов.
Идея: настраивается поведение пользователей, период теста и имитируется данный процесс. Вроде просто.
Проведение теста, близкого к реальной нагрузке - задача не совсем простая. Проблема в формировании корректного профиля поведения пользователя и в изменении профиля в зависимости от времени (например, профиль пользователя меняется во время распродаж для сайта online магазина). Тестирование это всегда аппроксимация, и близость к реальному поведению сегодня совсем не означает аналогичного через месяц. К тому же продукт обновляется, что приводит к изменениям структуры теста.
Поэтому тестирование подразумевает следующие этапы:
- Сборка логов
- Анализ логов в разрезе клиентов и времени, выявление усредненных шаблонов
- Формирование профилей пользователей
- Формирование тестовых сценариев
- Тестирование
- Сопоставление результатов с последующими реальными значениями
Установка стандартная
pip install locustЕсть web интерфейс.
Общая теория
Термин "производительность" очень часто основан на субъективном восприятии конечного пользователя.
KPI можно разделить на две группы: сервис-ориентированные и эффект-ориентированные. Сервис-ориентированные включают в себя доступность и время отклика. Эффект-ориентированные включают пропускную способность и емкость в пределах существующей инфраструктуры.
Black hat python
Затраты времени
Текущие задачи
Общая идея системы
Задачи в очереди
Следующий релиз
Решенные задачи
| Дата | Время | Задача | Тип задачи |
|
|
|
|
POC системы управления ботнетом
Архитектура системы

Общие требования
- Модульность
- Управление обновлениями
- Резервирование основного сервера
- Собственное шифрование данных
Основной сервер
- Docker, FastAPI, PostgreSQL
- Простое добавление резервных серверов
- Разграничение по endpoint для клиентов
- Блокировка клиентов при несанкционированной активности
- Динамическое управление фаерволом
- Индивидуальные сборки для каждого клиента
- Настройки и payload интегрированы в исполняемый файл
Admin console
- параметризованная и интерактивная консоли
- многоуровневая консоль в стиле juniper
Протокол взаимодействия сервера и консоли
Клиент
Перспективные опции
- web интерфейс
- Сервис модулей типа apt (например bmm)
- Магазин ботов
- TOR
- Продажа своих серверных мощностей
- Платные модули, оплата за подписку
- Интеграция с криптой
- Межботнет взаимодействие
Модули

VK
Стартовая информация
Сервисный ключ предоставляет доступ к группам. Если лимиты на количество запросов (3 в секунду)
Доступ к группам:
В комментариях поста отдается все, включая комментарии комментариев.
Авторизация
Общая схема взаимодействия
Участники:
- VK Mini App (frontend)
- VK (как источник авторизации)
- backend (FastAPI)
Поток:
[Frontend (VK Mini App)] → получает launch params от VK, отправляет их на backend
↓
[Backend] → проверяет подпись VK, верно - переданный от frontend vk_user_id корректен
↓
[Backend] → сохраняет / читает данные из БДПараметры, передаваемые в запросе:
vk_app_id, vk_are_notifications_enabled, vk_is_app_user, vk_is_favorite, vk_language, vk_platform, vk_ref, vk_ts, vk_user_id
JS:
async function auth() {
try {
const launchParams = await vkBridge.send('VKWebAppGetLaunchParams');
console.log('LAUNCH PARAMS:', launchParams);
} catch (e) {
console.error('VK AUTH ERROR:', e);
}
}
async function startApp() {
await vkBridge.send('VKWebAppInit');
await auth();
requestAnimationFrame(loop);
}
startApp();В переменной LaunchParams будут содержаться параметры для запроса на back
Streamlit
Основа
Интересная вещь для быстрого создания ненагруженных web приложений
Общее
Магические методы
Все объекты. Тип данных - по сути правило операций (функций) для одного типа. Для определения используемых при написании конструкций (например +, *, ...) используются магические методы. Очень интересная возможность.
Магические методы
1. Инициализация и управление объектом
| __new__(cls, ...) | Создание экземпляра (до __init__) |
| __init__(self, ...) | Инициализация объекта |
| __del__(self) | При удалении объекта (деструктор, вызывается редко) |
| __repr__(self) | Для разработчиков (repr()) — однозначное представление |
| __str__(self) | Для пользователей (str(), print()) — читаемое представление |
| __bytes__(self) | bytes() |
| __format__(self, spec) | format() и f-строки |
| __hash__(self) | hash() (если None — объект нехэшируемый) |
| __eq__(self, other) | == |
| __lt__(self, other) | < |
| __le__(self, other) | <= |
| __gt__(self, other) | > |
| __ge__(self, other) | >= |
| __bool__(self) | bool(), if obj: (если нет — проверяет __len__) |
| __len__(self) | len() |
| __contains__(self, item) | in (если нет — перебирает через __iter__) |
| __getitem__(self, key) | self[key], for i in obj: |
| __setitem__(self, key, value) | self[key] = value |
| __delitem__(self, key) | del self[key] |
| __iter__(self) | Итератор (for x in obj:) |
| __next__(self) | next() |
| __reversed__(self) | reversed() |
2. Арифметические операторы
Возвращается всегда новая переменная. Существует три варианта в случае арифметических операций:
- Базовый. Вызывается первым, для объекта слева. Объект справа может быть любого типа. Внутри нужно проверять принадлежность к классу для второго аргумента. В случае ошибки / несоответствия типов / ... вызывается NotImplemented.
class MyClass: def __add__(self, other): if isinstance(other, MyClass): return MyClass(self.value + other.value) elif isinstance(other, (int, float)): return MyClass(self.value + other) else: # Не знаю, что делать return NotImplemented - Если был вызван NotImplemented, право сделать что-то передается объекту справа (правые версии). Если правая версия не определена, то будет TypeError. Но если порядок не важен, можно сделать так:
class MyClass: ... def __radd__(self, other): return self.__add__(other) - Существует способ записи например += Для него может быть отдельный (расширенный) метод. Если не определять, то вызывается соответствующий базовый метод. Можно менять сам объект. Обязательно возвращать объект.
| Операция | Базовые методы | Правые версии | Расширенные версии | ||
| + | __add__(self, other) | __radd__(self, other) | other + self | __iadd__(self, other) | += |
| - | __sub__(self, other) | __rsub__(self, other) | other - self | __isub__(self, other) | -= |
| * | __mul__(self, other) | __rmul__(self, other) | other * self | __imul__(self, other) | *= |
| / | __truediv__(self, other) | __rtruediv__(self, other) | other / self | __itruediv__(self, other) | /= |
| // | __floordiv__(self, other) | __rfloordiv__(self, other) | other // self | __ifloordiv__(self, other) | //= |
| % | __mod__(self, other) | __rmod__(self, other) | other % self | __imod__(self, other) | %= |
| **, pow() | __pow__(self, other[, modulo]) | __rpow__(self, other) | other ** self | __ipow__(self, other) | **= |
| -obj | __neg__(self) | ||||
| +obj | __pos__(self) | ||||
| abs() | __abs__(self) | ||||
| round() | __round__(self[, n]) |
3. Битовые операторы
| Операция | Базовые методы | Правые версии | Расширенные версии | |
| & | __and__(self, other) | __rand__(self, other) | __iand__(self, other) | &= |
| | | __or__(self, other) | __ror__(self, other) | __ior__(self, other) | |= |
| ^ | __xor__(self, other) | __rxor__(self, other) | __ixor__(self, other) | ^= |
| << | __lshift__(self, other) | __rlshift__(self, other) | __ilshift__(self, other) | <<= |
| >> | __rshift__(self, other) | __rrshift__(self, other) | __irshift__(self, other) | >>= |
| ~ | __invert__(self) |
4. Методы для контекстного менеджера (``with``)
| __enter__(self) | Вход в контекст |
| __exit__(self, exc_type, exc_val, exc_tb) | Выход из контекста (с обработкой исключений) |
5. Работа с атрибутами
| __getattr__(self, name) | при обращении к несуществующему атрибуту |
| __setattr__(self, name, value) | при установке любого атрибута |
| __delattr__(self, name) | del obj.name |
| __getattribute__(self, name) | при обращении к ЛЮБОМУ атрибуту (осторожно, рекурсия!), редко используется |
| __dir__(self) | dir() |
| __hasattr__(self, name) | hasattr() (не нужен — __getattr__ обработает) |
6. Вызов объекта как функции
__call__(self, *args, **kwargs) # obj()
7. Работа с классами и метаклассами
| __init_subclass__(cls, **kwargs) | при создании подкласса |
| __set_name__(self, owner, name) | при создании дескриптора в классе |
| __prepare__(name, bases, **kwargs) | метакласс: подготовка пространства имён |
| __instancecheck__(self, instance) | isinstance() (для метаклассов) |
| __subclasscheck__(self, subclass) | issubclass() (для метаклассов) |
8. Дескрипторы (управление атрибутами другого класса)
__get__(self, instance, owner) # получить атрибут
__set__(self, instance, value) # установить атрибут
__delete__(self, instance) # удалить атрибут
9. Сериализация
| __reduce__(self) | pickle (возвращает (callable, args[, state])) |
| __reduce_ex__(self, protocol) | расширенная версия для pickle |
| __getstate__(self) | что сохранять в pickle |
| __setstate__(self, state) | восстановление из pickle |
10. Математические и другие
| __complex__(self) | complex() |
| __int__(self) | int() |
| __float__(self) | float() |
| __index__(self) | для преобразования в int (для срезов, bin(), hex()) |
| __trunc__(self) | math.trunc() |
| __floor__(self) | math.floor() |
| __ceil__(self) | math.ceil() |
| __matmul__(self, other) | @ (матричное умножение в Python 3.5+) |
| __rmatmul__(self, other) | right @ |
| __imatmul__(self, other) | @= |
11. Асинхронные методы (async/await)
| __await__(self) | await obj |
| __aiter__(self) | async for |
| __anext__(self) | async next() |
| __aenter__(self) | async with |
| __aexit__(self, exc_type, exc_val, exc_tb) | async with exit |
Самые частые методы:
`__init__`, `__str__`, `__repr__` — 90% обычных классов
`__add__`, `__radd__`, `__iadd__` — для своего класса с `+`
`__getitem__`, `__setitem__`, `__len__` — чтобы объект вёл себя как коллекция
`__enter__`, `__exit__` — для `with`
`__call__` — сделать объект вызываемым (как функция)
`__eq__`, `__lt__`, `__hash__` — для сравнения и словарей