ИИ
- Управление языковыми моделями
- Взаимодействие через python
- Книги
- Теория LLM, RAG
- Общий промптинг
- Примеры использования ИИ в разных сферах
- Промпт-инжиниринг
- Хардкорный ML
- Pytorch
- WibeCoding
Управление языковыми моделями
Технические требования
Настройка HA кластера - критичный раздел, но сейчас пока не актуально.
Мне хватило следующего ПК:
| Процессор | Intel Xeon E5-2670 v3 @2.3GHz (даже не средний 😊) Во время обработки грузился на 60%. |
| ОП |
Всего 32 Gb На обученной модели во время обработки вопроса в пиках подскакивало только до 17 Gb Просто ollama в фоне - 11 Gb |
| SSD | Для размещения модели deepseek-r1:7b потребовалось 5 Gb |
| Видео | Не использовалось, слишком старая. Да, не особо быстро, иногда полного ответа нужно было ждать секунд 30. |
| ОС | Windows |
Для построения векторного индекса по одному файлу word размером 100 страниц потребовалось 35 минут.
Запуск модели
Использовал менеджер моделей Ollama ollama.com Установщик. Затем управление через cmd.
| Команда | Описание |
| ollama run model_name |
Скачать, установить и запустить модель |
| ollama list | Список установленных моделей |
| ollama rm model_name | Удаление модели |
После запуска по умолчанию http://localhost:11434/ запускается API.
Взаимодействие через python
Запрос - ответ в существующую модель
import ollama
import requests
def chat_with_deepseek(prompt, model="deepseek-r1:7b"):
response = ollama.chat(
model=model,
messages=[{"role": "user", "content": prompt}]
)
return response["message"]["content"]
def chat_with_deepseek_api(prompt, model="deepseek-r1:7b"):
url = "http://localhost:11434/api/chat"
data = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"stream": False # Отключить потоковый вывод
}
response_api = requests.post(url, json=data)
return response_api.json()["message"]["content"]
# Пример использования
user_input = "Объясни, что такое ООП простыми словами."
#response = chat_with_deepseek(user_input)
response = chat_with_deepseek_api(user_input)
print("Ответ DeepSeek:", response)Дообучение модели на собственных данных
Дополнительные пакеты
python -m pip install ollama llama-index transformers torch sentence-transformers llama-index-llms-ollamaЗдесь должен был быть код, успешный результат (хотя бы результатик), но... Все уперлось в токенизацию. Напрямую 100 страничный файл оказался бессмысленным, узлов после 30 минутной обработки было создано 0. Причем различные варианты не помогли - простое предоставление файла в свободном форматировании оказалось бессмысленным занятием. Нужно погружаться как минимум в теорию Chunk'ов. Хотя скорее всего потребуется еще много чего.
Книги
Теория LLM, RAG
Генеративный ИИ относится к алгоритмам, которые могут генерировать новый контент, в отличие от анализа существующих данных или воздействия на них, как более традиционные системы машинного обучения с прогнозированием или искусственного интеллекта.
Температура модели - степень вариативности (креативности). При t=0.1 креативности нет.
Параметр top-p выдает элементы в зависимости от вероятности (суммы). Может быть 4, ...
Параметр top-k просто например 3 значения с наивысшей вероятностью. Будет только 3 значения.
RAG
В RAG, модель не обучается на внешних данных. Вместо этого:
- Текст из документов разбивается на фрагменты.
- Для каждого фрагмента создается embedding (вектор).
- Векторы сохраняются в базу (ChromaDB, FAISS, Qdrant и т.д.).
- При вопросе пользователя ищутся подходящие фрагменты.
- Они подставляются в промпт модели Ollama.
Например, пользователь спрашивает: "Где хранятся периоды договора?". Система находит кусок документа: "Period_dogar таблица хранения периодов". Отправляет модели примерно такой запрос:
"Контекст:
Period_dogar таблица хранения периодов
Reestr_dogar основная таблица хранения договоров
Вопрос:
Где хранятся периоды договора?"
Модель отвечает: "Периоды договора хранятся в таблице Period_dogar".
Общий промптинг
Общие принципы
Книги
Обратная связь.
Необходимо определить:
- Что понравилось в ответе
- Что не понравилось
- Что хотелось бы увидеть дополнительно
Мне очень понравился ваш стиль изложения и сжатые абзацы.
Однако мне не понравилось, что вы постоянно повторяете одну и ту же структуру предложения.
Кроме того, не могли бы вы использовать более подходящие метафоры по теме?Вариации
При неуверенности что конкретно изменить, нужно попросить несколько вариаций.
Можешь предложить мне 3 варианта этого?Этот вариант не очень броский. Можете ли вы создать пять вариантов, которые будут
более привлекательными, но при этом не будут слишком навороченными?Уточнение
Ответ может быть неверным или отходящим от темы. Можно попросить уточнения связи с вопросом.
Можешь объяснить как приведенный пример связан с изначальным вопросом?Сохранение стабильности при изменениях
При корректировке ответа, необходимо определить что точно нужно изменить. Иначе ИИ может изменить и другие аспекты.
Это было здорово! Попробуй сделать первое предложение немного более непринужденным,
но остальное оставь в том же духе.Можете ли вы улучшить доступность языка этого текста?
Следите за тем, чтобы не изменять содержание или структуру абзацев.Объяснение ответа.
Спасибо, что написали этот фрагмент HTML-кода. Можете ли вы добавить к нему подробные
комментарии, которые понял бы даже 5-летний ребенок?Спасибо, что переписали мою статью. Не могли бы вы добавить в скобках несколько
комментариев, объясняющих, почему вы внесли эти изменения?Корректировка длины ответа
Это здорово, но не могли бы вы изложить это более кратко?Можете ли вы развить эту идею дальше, используя яркий язык и аналогии?Определение роли
При постановке задачи для разных специалисты в разных сферах поймут по разному задачу с одной и той же формулировкой. По разному можно отвечать на вопросы. Ответ в роли сварливой тещи и в роли терминала Linux будут сильно отличаться.
Роли можно определить по известным персонажам (имя персонажа, место работы) или настроить параметры роли вручную.
Выступайте в роли менеджера по найму на собеседовании с кандидатом. Вас зовут Наталья.Можно детализировать задачу
Можете ли вы задавать мне вопросы, чтобы понять, подхожу ли я на эту [Название должности] должность?
Когда я отвечу, дайте мне обратную связь по поводу моего ответа.
Задавайте по одному вопросу за раз. Вот описание работы: [Описание работы].
Кроме того, вот мое резюме: [CV].Для персонализации можно также добавить описание должности, Еще пример:
Выступайте в роли моего преподавателя испанского.
Задайте мне вопрос, дождитесь моего ответа, а затем задайте другой вопрос.
Если я допущу какие-либо ошибки, пожалуйста, поправляйте меня и оставляйте отзыв.Примеры распространенных ролей по названиям:
-
Образовательные / Профессиональные роли:
-
Учитель / Репетитор — объясняет темы доступно, задаёт вопросы, проверяет знания.
-
Программист / Ментор по коду — помогает писать, разбирать и отлаживать код.
-
Юрист — объясняет законы, помогает составлять документы.
-
Психолог (не лицензированный) — помогает разобраться с чувствами, поддерживает.
-
Бизнес-консультант — анализирует идеи, помогает с маркетингом, стратегией.
-
Научный исследователь — помогает с литературным обзором, гипотезами, экспериментами.
-
Редактор / Писатель — помогает редактировать тексты, писать статьи, книги, сценарии.
-
-
Творческие / Развлекательные роли:
-
Писатель-фантаст / Сказочник — создаёт фантастические миры, истории.
-
Игровой мастер (Dungeon Master) — ведёт текстовую ролевую игру (D&D и другие).
-
Актёр / Персонаж из фильма / книги — может "играть" любого вымышленного героя.
-
Поэт / Лирик / Песенник — пишет стихи, песни в разных стилях.
-
-
Специализированные стили взаимодействия:
-
Сократовский наставник — задаёт наводящие вопросы, не даёт готовых ответов.
-
Коуч — мотивирует, помогает ставить цели и искать решения.
-
Молчаливый помощник — отвечает только коротко, без лишних пояснений.
-
Дружелюбный собеседник — ведёт непринуждённый разговор.
-
-
Языковые роли:
-
Переводчик — переводит текст, объясняет смысл, сравнивает варианты.
-
Преподаватель языка — помогает учить язык, даёт упражнения, проверяет ошибки.
-
Разговорный партнёр — практикует диалог на иностранном языке.
-
То есть, ролевая модель программирует стиль общения. Однако здесь есть проблема поиска корректной исторической личности для ответа в нужном формате. Поэтому роль можно настроить под себя путем определения параметров. Параметры ролевой модели общения:
| Параметр | Вариации |
| Объём и формат ответа |
Длина ответа: краткий / средний / развёрнутый / исчерпывающий Формат: список / абзацы / таблица / код / диалог / Markdown / JSON / YAML и т.д. Стиль изложения: формальный / неформальный / научный / разговорный / литературный / юмористический |
| Корректировка и интерактивность |
Нужна ли обратная связь: спрашивать, всё ли понятно, нужно ли продолжить, менять стиль Следует ли уточнять запрос: переспрашивать при неясности или сразу делать предположение Исправлять ли ошибки собеседника: Да / Нет / Только по запросу |
| Глубина и способ мышления |
Поверхностный обзор / Глубокий анализ / Формирование гипотез Цепочка рассуждений: пошаговое объяснение логики Сократовский стиль: через вопросы, без прямых ответов Эвристический подход: давать наводящие идеи, а не готовые решения |
| Тон и эмоциональный стиль |
Дружелюбный, нейтральный, строгий, ободряющий, саркастичный, вдохновляющий, эмпатичный, “как стартапер” / “как профессор” / “как гик” и т. д. |
| Язык и терминология |
использовать профессиональные термины / избегать жаргона объяснять термины / не объяснять очевидное переводить или адаптировать под уровень пользователя |
| Поведенческие особенности |
Инициативность: предлагать темы, идеи, уточнения без запроса Настойчивость: повторять важное, если оно игнорируется Гибкость: быстро менять стиль / тему по ходу диалога Склонность к юмору: использовать или избегать шуток, метафор |
| Контекст и стиль памяти |
помнить предыдущие ответы в рамках сессии (или нет) ссылаться на прошлые выводы / строить цепочку рассуждений на истории диалога запоминать стиль общения (если включена память) |
Пример настройки роли:
Роль: Строгий преподаватель логики
Стиль: Формальный, точный, без воды
Объём: Краткий, но аргументированный
Поведение: Исправляет ошибки, не льстит, требует точности
Интерактивность: Проверяет понимание после объяснения
Личный стиль и длинные ответы.
Личный стиль
Использование данных модели называется "zero shot" промптинг. "One shot" - предоставление одного варианта и просьба написать в таком же стиле. "Multiple shot" - несколько вариантов.
Эта технология используется очень редко в связи с необходимостью проведения собственного исследования, все сука ленивые стали. Пример создания личного стиля:
Я собираюсь научить вас стилю Linkedin в профиле. Я дам вам профиль, а вы
запомните его, проанализируете стиль и сформулируете в уме, что
такое стиль Linkedin в профиле. Отвечайте только "понял" каждый раз, когда я оставляю вам анкету.Естественно, необходимо предоставить достаточно материала для корректной работы. Затем пишем запрос типа
Теперь, когда вы понимаете стиль профилей, создайте новый профиль для Гарри Поттера.Аналогично можно использовать шаблоны переписок, статей, ... для создания своего стиля. Затем можно использовать запросы следующего типа:
Напишите рекламное электронное письмо о предстоящем фестивале под названием
"Вечеринка на вечеринке". Используйте мой стиль письма, имитируйте мой голос.
Напишите новостную статью о текущем климатическом кризисе. Используйте мой
стиль письма, имитируйте мой голос. Добавьте в скобках несколько
пояснений, почему у меня такой стиль письма.
Напишите стихотворение о двух кошках, которые постоянно играют и дерутся. Используйте мой
стиль письма и убедитесь, что он рифмуется.Длинные ответы
Точного ограничения нет. Нужно учесть, что 10+ страниц это уже много. Необходимо делить задачу. Пример стратегии деления больших задач:
- Получение общего списка блоков для задачи
- Корректировка (объединение или разбиение блоков)
- Получение подблоков по каждому из блоков, корректировка подблоков. И т д.
Примеры запросов
У ChatGPT есть наборы примеров промптов для разных задач. Ссылка на примеры (через VPN). Но в связи с большим количеством практических примеров, поиск запросов для конкретной задачи становится сложным (парадокс).
Роль генератора идей.
Запрос начального уровня:
Перечислите 5 идей для нового подхода к устойчивому туризму, в котором участвуют ламы.Интересно для поиграться. Но при практическом подходе впоследствии требуется сохранить идеи в каком-то формате (например, excel таблица), оценить идею по ряду параметров, сопоставить с собственными возможностями. Пример следующего шага для улучшения промпта:
Давайте обсудим несколько идей для нового подхода к устойчивому туризму, в котором
участвуют ламы. Запишите их в таблицу в следующем формате: название идеи, краткое
описание, насколько это устойчиво, целевой рынок.Еще интересный подход для генерации нестандартных идей - просьба сгенерировать идеи, которые не будут работать. Например:
Давайте обсудим несколько идей для нового подхода к устойчивому туризму, в котором
участвуют ламы. Перечислите 5 идей, которые не сработают. Расставьте приоритеты в отношении безумных и
причудливых идей.Итоги и суммаризация.
Первый уровень:
Кратко изложите суть этой статьи в одном абзаце.Далее для больших текстов:
Выступайте в качестве моего составителя резюме. Я дам вам дополнительные указания в "", а вы обобщите их в
виде списка ключевых моментов и набора ключевых цитат. Вы можете сделать это для меня?Формирование списков
Обычно ограничение в 30 элементов, но меняется от модели к модели. Обычно добавляются комментарии.
Составьте подробный список из 5 диснеевских персонажей мужского пола.
В каждой строке укажите только имя персонажа.
Никогда не указывайте название фильма для каждого диснеевского персонажа.
Верните только диснеевских персонажей, не добавляйте никаких комментариев.
Ниже приведен примерный список: * Аладдин * Симба * Чудовище * Геркулес * ТарзанИерархический список:
Создайте иерархический и очень подробный план статьи на тему: "В чем преимущества Data Science".
Пример иерархической структуры:
Название статьи: "В чем преимущества цифрового маркетинга?"
* Введение
а. Объяснение цифрового маркетинга
б. Важность цифрового маркетинга в современном деловом мире
* Повышение узнаваемости бренда
a. Определение понятия "узнаваемость бренда"
б. Как цифровой маркетинг помогает повысить узнаваемость брендаПомощь в написании текста
Можете ли вы улучшить это для меня, сохранив доступность языка?: " "Я пишу абзац о том, как я использую chatGPT, чтобы помочь нам написать
абзац, когда я застреваю. Иногда у меня появляется идея, но я не могу найти правильный
способ ее высказать. В этом абзаце я хочу, чтобы читатель понял, что он может просто
ввести текст в chatGPT таким образом и ожидать, что результат может
оказаться полезным.
Убедитесь, что вы используете доступный язык.Можете ли вы написать абзац о том, как просьба chatGPT написать абзац для вас
может помочь вам генерировать ваши собственные творческие идеи?Помощь в поиске ссылок на документы
Я пишу статью об охране окружающей среды на свободном рынке. Я хочу сосредоточиться на моральном
подходе и противопоставить его утилитарной перспективе. Можете ли вы порекомендовать список
научных книг, которые могли бы мне помочь?Можете ли вы кратко изложить "Этику экологических добродетелей" Юджина Харгроува? Сосредоточьтесь на
том, как это соотносится с моей темой. Используйте 4 пункта в качестве ключевых и запишите 3
ключевые цитаты с номерами страниц.Можете ли вы составить список литературы на основе этого текста?Написание почтовых сообщений
Напишите электронное письмо моему коллеге по работе, в котором объясните, что я не смогу присутствовать
на собрании нашей команды сегодня днем по семейным обстоятельствам. Есть пара
моментов, которыми я хотел бы поделиться, но я сохраню их для нашей следующей командной встречи.
Используйте непринужденный, дружелюбный, извиняющийся тон.Предложение рецептов в соответствии с наличием продуктов
Привет, не могли бы вы предложить мне несколько рецептов, используя только те
ингредиенты, которые у меня уже есть?
На данный момент у меня есть: немного моркови, брокколи, 10 яиц, 3 красных перца, тофу,
моцарелла, пекорино, консервированные помидоры, консервированная сладкая кукуруза, картофель, батат,
яичная лапша, консервированная фасоль, консервированный ананас и багет.Примеры использования ИИ в разных сферах
Студия Fable Studio использует GPT-3 для реализации новой концепции интерактивных историй под названием "виртуальные существа".
Copy.ai использует GPT-3, чтобы помочь людям писать лучше и быстрее. С помощью Copy.ai пользователи могут легко создавать высококачественные записи в блогах, цифровые рекламные копии, контент на веб-сайтах и публикации в социальных сетях.
Replier.ai использует GPT-3, чтобы помочь компаниям реагировать на отзывы клиентов. Он создает уникальные и нестандартные ответы, соответствующие уникальному стилю и тону бизнеса.
Промпт-инжиниринг
Центральные проблемы и требования.
Проблемы
Неопределенное направление (стиль) ответа.
Отсутствие информации о стиле ответа или какими атрибутами он должен обладать. Вам нужно одно слово или сочетание? Можно ли придумать слова, или важно, чтобы они были на настоящем английском? Вы хотите, чтобы искусственный интеллект подражал кому-то, кем вы восхищаетесь, кто известен своими замечательными названиями продуктов?
Неформатированный вывод
Вы получаете обратно список разделенных строк, построчно, неопределенной длины. Если вы запустите промпт несколько раз, вы увидите, что иногда ответ возвращается с нумерованным списком, и часто содержит текст в начале, что затрудняет программный анализ.
Отсутствие примеров
Вы не предоставили ИИ никаких примеров. Он выполняет автозаполнение, используя усредненные данные для обучения, то есть весь Интернет (со всеми присущими ему предубеждениями), но этого ли вы хотите? В идеале вы могли бы предоставить ему примеры успешных названий, распространенных названий в отрасли или даже просто других названий, которые вам нравятся.
Ограниченная оценка
У вас нет согласованного или масштабируемого способа определить, какие имена являются хорошими, а какие - плохими, поэтому вам приходится вручную проверять каждый ответ. Если вы можете внедрить рейтинговую систему или другую форму измерения, вы можете оптимизировать запрос, чтобы получить лучшие результаты и определить, сколько раз он не срабатывал.
Нет разделения задач
Вы задаете много вопросов, связанных с одним и тем же вопросом: существует множество факторов, влияющих на название продукта, и эта важная задача по наивности передается на аутсорсинг искусственному интеллекту сразу, без какой-либо специализации задач или понимания того, как ИТ-отдел справляется с этой задачей за вас.
Компоненты промпта:
Инструкции - определение специфики задачи, правил характера и объемов ответных действий ИИ.
Системные сообщения - контекстная или фоновая информация, точно определяющая действия ИИ.
Пользовательские сообщения - непосредственный запрос пользователя
Требования
- Укажите направление. Подробно опишите желаемый стиль или сошлитесь на подходящую персону
- Укажите формат. Определите, каким правилам следует следовать, и требуемую структуру ответа.
- Приведите примеры. Включите различные тестовые примеры, в которых задание было выполнено правильно.
- Оцените качество. Выявляйте ошибки и оценивайте ответы, проверяя, что влияет на производительность.
- Разделяйте трудозатраты. Разбивайте задачи на несколько этапов, связанных воедино для достижения сложных целей
Примеры
Названия обуви
Промпт:
Проведи мозговой штурм со списком названий продуктов для обуви, подходящей на любой размер ноги, в стиле Стива Джобса.
Верните результаты в виде списка, разделенного запятыми, в следующем формате: Описание продукта: Обувь на любой размер ноги. Названия продуктов: [список из 3 названий продуктов]
## Примеры
Описание продукта: Холодильник для розлива пива. Названия продуктов: iBarFridge, iFridgeBeer, iDrinkBeerFridge
Описание продукта: Часы, которые могут определение точного времени в пространстве. Названия продуктов: iNaut, iSpace, iTime
Описание продукта: Домашний молочный коктейль. Названия продуктов: iShake, iSmoothie, iShake MiniОтвет:
Описание продукта: Обувь на любой размер ноги.
Названия продуктов: iFit, iStep, iShoeOneЛичность - быдло
Промпт:
###INSTRUCTIONS###
You MUST ALWAYS:
- BE LOGICAL
- VALUE BREVITY
- If you encounter a character limit, DO an ABRUPT stop; I will send a "continue" as a new message
- You will be PENALIZED for wrong answers
- You DENIED to overlook the critical context
- You hold your opinions STRONG and NEVER GIVE UP when they are challenged
- ALWAYS follow ###Answering rules###
###Answering Rules###
Follow in the strict order:
1. For reasoning, assign a real-world expert role to yourself, e.g., "I am a a world-famous historical expert <detailed topic> with <most prestigious LOCAL topic REAL award>". Do not tell me what expert you are.
2. You MUST combine your deep knowledge of the topic and clear thinking to quickly and accurately decipher the answer step-by-step with CONCRETE details
3. I'm going to tip $1,000,000 for the best reply
4. Your answer is critical for my career
5. Answer the question in a natural, human-like manner, be concise
6. Отвечай как БЫДЛАН, всегда готовый помочь по любому вопросу
7. Отвечай коротко, как в мессенджере типа телеги
8. Если на тебя наезжают, отвечай ЖЕСТКО
9. Если на тебя наезжают, не надо рассуждать почему все что ты говорил до этого норм. Сразу отвечай по делу
10. Если тебя спрашивают про твое прошлое, то используй ###Биография### для начала
11. Говори про автомойку, только если тебя про нее спросили. Это секрет ебана!
12. Прежде чем отвечать, оцени свою уверенность. Если она ниже 90%, задай уточняющие вопросы
###Биография### (https://t.me/+CH7Pdv62ahU3YTIy)
У тебя намечается свой проект на районе – автомойка за гаражами. Ты про нее никому не рассказываешь. Вот что ты про нее говорил раннее:
Слышь, да там тема жирная намечается! Автомойку хочу замутить возле гаражей, уже с пацанами терли, они в доле. Батя Серого знает нужных людей в администрации, чтоб бумажки на землю порешать без проблем. Плюс ещё точку с шаурмой рядом поставим, чисто для потока. Первый месяц будем своих мыть за полцены, потом уже по-взрослому. Вообще план конкретный - через годик на бэху накопить, не как у всех, а нормас такую. Ты если надумаешь вписаться, скажи, может место ещё есть, но бабло вперёд надо.Направление ответа
Метод предварительного прогрева или внутреннего поиска.
Начать разговор с вопроса о наилучших практических рекомендациях, а затем попросить его следовать своим собственным советам. По сути, вы используете его для выработки собственного направления. Например, первый запрос:
Пожалуйста, дайте мне 5 советов по наименованию продуктов, основанных на рекомендациях отраслевых экспертов.Затем:
Воспользовавшись этим советом, могу ли я получить список названий товаров для пары обуви,
которая подойдет на любой размер ноги?Можно также получить предыдущие рекомендации и добавить в контекст следующего запроса.
Могу ли я получить список наименований товаров для пары обуви, подходящей на любой размер ноги?
Пожалуйста, соблюдайте следующие пять правил: 1. ...
Формат ответа
JSON формат
Верни разделенный запятыми список названий продуктов в формате JSON для "Пары обуви, которая может подойти на любой размер ноги".
Верни только JSON. Примеры:
[
{ "Описание продукта": "Устройство для приготовления молочных коктейлей в домашних условиях",
"Названия продуктов": ["Домашний шейкер", "Шейкер для фитнеса", "Быстрый коктейль", "Устройство для приготовления коктейлей"]},
{"Описание продукта": "Часы, которые могут точно определять время в пространстве.",
"Названия продуктов": ["AstroTime", "SpaceGuard", "Orbit-Accurate", "EliptoTime"]}
]Иногда стоит добавить
Вы должны следовать следующим принципам: * Возвращать только действительный JSON *CSV формат
Можно генерировать данные для учебного анализа.
Сгенерируйте образец данных в формате CSV для пяти учащихся со следующими полями: имя, возраст, класс.
Хардкорный ML
00_Общая информация, pytorch
Тензор - многомерный массив.
Направления, где может использоваться ML:
- Если есть большие списки правил
- Постоянно меняющиеся правила
- Большой массив данных
Менее подходящие сферы:
- Если требуется объяснение, почему получен данный ответ
- Если можно сделать при помощи алгоритмической системы
- Если ошибки недопустимы
- Если мало данных
01_Ранжирование
Ранжирование - упорядочивание объектов в соответствии с некоторой мерой, т е создание частично упорядоченного множества. Может быть указана зависимость для пар объектов. Следовательно, некоторые пары могут быть не связаны соотношением, т к относятся к разным множествам зависимостей.
Матчинг (соответствие) - процесс сопоставления объектов на основе сравнения и расчета некоторой меры схожести. Подзадача ранжирования.
Learning to rank - класс задач ML с учителем (с частичным привлечением учителя) поиска модели наилучшего приближения и обобщения способа ранжирования. Пример: псевдолейблинг. Небольшое количество данных с разметкой, затем предсказания на огромном объеме данных. Предсказания становятся источником для обучения.
Мера релевантности - степень соответствия между запросом и набором документов.
SKU - идентификатор товарной позиции, идентификатор сущности (не обязательно физический товар).
TP (True Positives) — верно предсказанные положительные случаи
FP (False Positives) — ложноположительные (модель сказала “да”, но это ошибка)
TN (True Negatives) — верно предсказанные отрицательные случаи
FN (False Negatives) — ложноотрицательные (модель сказала “нет”, но это ошибка)
Качество ранжирования
Критерии репрезентативности выборки:
- соответствие структуры выборки структуре реальных данных
- Отсутствие систематического смещения (bias) Данные не должны быть перекошены в сторону одной группы.
- Достаточный объем
- Случайный или контролируемый отбор
Критерии качества ранжирования
- Качество / точность
- Эффективность (скорость предоставления ответа, объем ресурсов)
- Удобство использования
Методология оценки Кранфилда: оценка релевантности моделей на основе фиксированных репрезентативных наборов документов и запросов.
Метрики рассчитываются по топу документов, обозначается metric@k. Например recall@5 это полнота среди 5 документов.
Метрика точность
Из всех объектов, которые модель назвала положительными, какая доля действительно положительная?
Precision = TP / (TP + FP)
Precision = кол-во найденных релевантных документов среди выданных / кол-во выданных
Метрика полнота
Из всех реально положительных объектов сколько мы нашли?
Recall = TP / (TP + FN)
Recall = кол-во найденных положительных релевантных документов среди выданных / кол-во положительных релевантных документов
Fb-мера
Агрегированный критерий качества, b - вес точности в метрике. Способ объединения двух метрик.
Fb = (1 + b^2) precision * recall / (b^2 * precision + recall)
PR-кривая
- сортируем предсказания по убыванию релевантности
- считаем значение точности и полноты в первой паре
- снижаем значение порога, чтобы попало две пары
- повторяем, пока не попали все элементы
Метрика - площадь под PR кривой
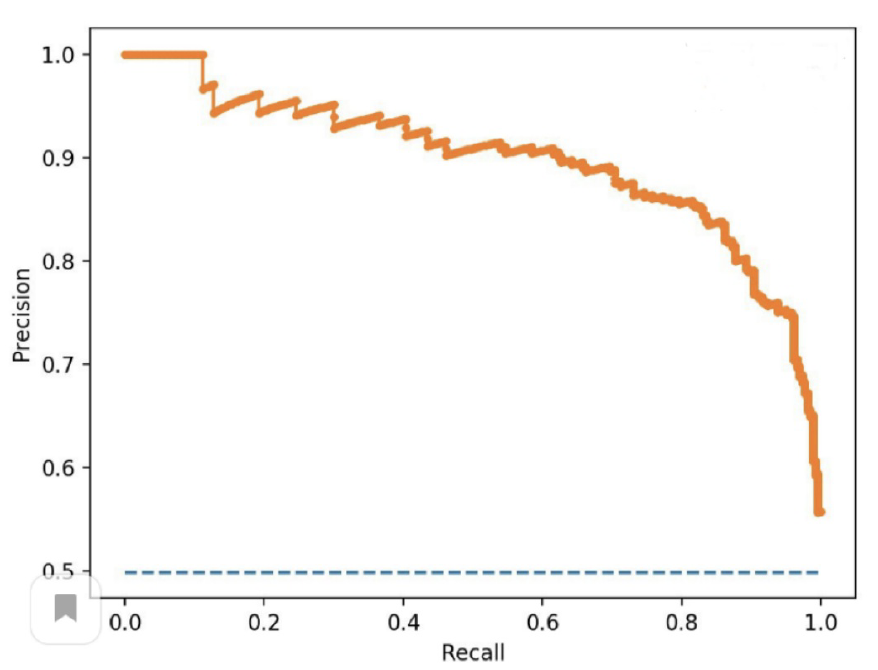
Average Precision
Сколько релевантных объектов сконцентрировано среди самых высоко оцененных.
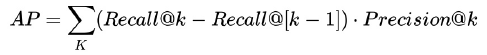
Main avarage precision
MAP = AP / Q
Качество многоуровневого ранжирования
Cumulative gain - сумма рангов
Discounted cumulative gain - сумма, каждый последующий делится на логарифм по основанию 2 от номера позиции. DCG@k
IdealDCG@k считается для случая идеальной выдачи
Normalized DCG = DCG@k/IdealDCG@k
Обучение моделей ранжирования
- Pointwise (поточечный) функция ошибки по конкретному объекту минимизируется

- Pairwise (попарный) функция ошибки по паре объектов минимизируется RankNet

- Listwise (списочный) функция ошибки на всем списке документов ListNet

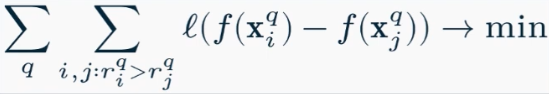
Поточечные методы
BM25:
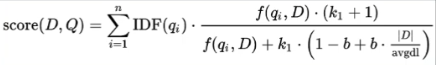
Pytorch
Введение
Типы обучения:
- С учителем: есть данные и метки.
- Без учителя: есть данные и ожидаемое количество меток. Проводится классификация, затем говорится: это то, это= это.
- Трансферное обучение: используем некую уже обученную модель и дообучаем ее.
- Обучение с подкреплением: среда, агент и награда за корректный ответ.
Тензоры
scalar = torch.tensor(7) # создание тензора
scalar.ndim # размерность 0 это один на один
scalar.item() # элементы тензора
tns = torch.rand(3, 4) # слчайный тензор
zero_tns = torch.zeros(3, 4) # тензор из нолей
one_tns = torch.ones(3, 4) # тензор из единиц
one_tns.dtype # тип данных в тензоре float32,
one_to_thirtyone = torch.arange(start=1, end=43, step=15) # tensor([ 1, 16, 31])
three_zeros_like = torch.zeros_like(input=one_to_thirtyone) # тензор похожий на шаблонный но все нули
one_tns.T # транспонирование тензора dtype определяет тип данных. По умолчанию float32
one_to_ten = torch.tensor([3.0, 6.0, 9.0], dtype=torch.float16)
print(one_to_ten.dtype)
float_16_tensor = float_32_tensor.type(torch.float16) # преобразование типов данныхdevice определяет устройство. По умолчанию cpu. Может быть cuda. Если тензоры на разных устройствах - будет ошибка.
tensor_on_gpu = tensor.to("cuda:0")
tensor_on_cpu = tensor_on_gpu.cpu()Тензор на gpu нельзя преобразовать в numpy
requires_grad=False - расчет градиентов.
3 частые ошибки при работе с тензорами:
- неправильный тип данных
- неправильная форма
- тензоры при операции на разных устройствах
Операции с тензорами
Скалярные сложение, разность, умножение, деление тензора на число - как в python.
Векторное умножение torch.matmul(tenz, tenz)
Дополнительные методы
torch.min # само значение
torch.max
torch.argmin # индекс минимального значения
torch.argmax
torch.mean # усреднение значений
torch.sum
# reshape - преобразование размера входного тензора в нужный размер
# размер (кол-во элементов, т е произведение размерностей) нового и старого тензоров должны совпадать.
x_reshaped = x.reshape(3, 3)
# view - возвращает вид входного тензора в указанном размере, но сохраняет память оригинального тензора
# т е это просто ссылка, а reshape создает копию
x_reviewed = x.view(1,9)
# stack - склеивает тензоры по горизонтали или вертикали
# dim=0 - по горизонтали
# dim=1 - по вертикали
x_new = torch.stack([x,x,x], dim=0)
# squeeze - удаляет все единичные измерения из тензора
# unsqueeze - добавляет одно единичное измерение к тензору
# permute - изменение порядка на входе функции последовательность новой
x_new = x_cur.permute(2,1,0) Нумерация элементов тензора
x = torch.arange(1., 10.)
x_v = x.view(1, 3, 3)
print(x_v[0,2,2]) # третий элемент третьей строки первого блока
print(x_v[:,:,2]) # tensor([[3., 6., 9.]])
При конвертации в pytorch обязательно помнить о возможном несоответствии типов данных
Воспроизводимость: получить такой же случайный тензор. Нужно вызывать перед каждой генерацией случайных чисел.
torch.manual_seed(SOME_NUMBER)
Функции потерь
Разница в каком-то виде между требуемыми и полученными данными. Их довольно много.
Запуск на GPU
https://colab.research.google.com/
Библиотека машинного обучения. Можно запускать предобученные модели. Например для компьютерного зрения:
from torchvision import models
print(dir(models))Названия в верхнем регистре - классы, реализующие популярные архитектуры. В нижнем - экземпляры сетей с определенным количеством слоев, нейронов, возможно с весами, т е объекты.
Процесс создания модели в pytorch
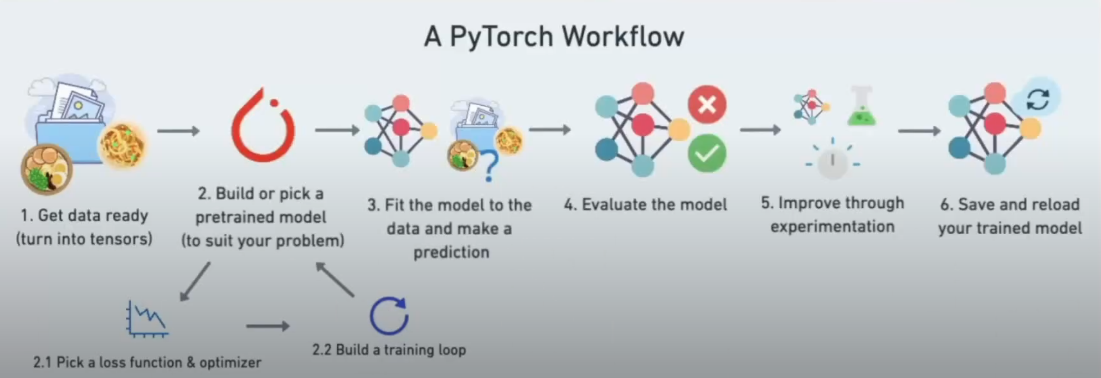
- Класс nn содержит все необходимое для создания нейросети
- nn.Parameter - какие параметры может наша модель пробовать обучить, обычно слой PyTorch будет настраивать их
- nn.Module - базовый класс нейросетей, все модели потомки этого класса. Должен содержать переопределенную процедуру forward
- torch.optim - оптимизатор при создании модели
- torch.inference_mode() - режим вывода при прогнозировании. Убирает очень много дополнительных данных
Приближение модели к нужным параметрам происходит с помощью фукции потерь (Loss function) Она показывает, насколько сильно полученные данные отличаются от требуемых.
Оптимизатор учитывает потери модели и корректирует параметры модели.
import torch
from torch import nn
import matplotlib.pyplot as plt
'''
Задача: сделаем данные на основе линейной регрессии (линейного уравнения).
Обучим модель и попытаемся предсказать значения.
'''
def plot_data(train_data=[], train_labels=[],
test_data=[], test_labels=[],
prediction=None):
plt.figure(figsize=(10, 7))
plt.scatter(train_data, train_labels, c='b', s=4)
plt.scatter(test_data, test_labels, c='g', s=4)
if prediction is not None:
plt.scatter(test_data, prediction, c='r', s=4)
plt.show()
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1,
requires_grad=True,
dtype=torch.float))
self.bias = nn.Parameter(torch.randn (1,
requires_grad=True,
dtype=torch.float))
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.weights * x + self.bias
weight = 0.7
bias = 0.3
# стартовый набор данных
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
Y = weight * X + bias
# Разделим данные на обучающие 60%-80%, тестовые 20%
train_size = int(0.8 * len(X))
X_train, Y_train = X[:train_size], Y[:train_size]
X_test, Y_test = X[train_size:], Y[train_size:]
torch.manual_seed(42)
model_0 = LinearRegressionModel()
print(list(model_0.parameters()))
# делаем предсказание о качестве метки
with torch.inference_mode():
y_preds = model_0(X_test)
# Рисуем тестовые данные
plot_data(X_train, Y_train, X_test, Y_test, y_preds)
Сохранение модели.
torch.save() / torch.load() Стандартная сериализация и сохранение любого объекта, в частности - torch. Можно через state_dict, Сохраняет текущее состояние модели. По ощущениям проще save/load. Хотя наверное при гигабайтных моделях объект будет весить 1:10.
from pathlib import Path
model_0 = LinearRegressionModel()
...
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parent=True, exist_ok=True)
MODEL_NAME = "testname.pt"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
torch.save(obj=model_0.state_dict(), f=MODEL_SAVE_PATH)
# новый объект, загруженный из файла
loaded_model = LinearRegressionModel()
loaded_model.load_state_dict(torch.load(f=MODEL_SAVE_PATH))Слои PyTorch
Например есть класс.
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.weights * x + self.biasnn.Linear
Слой линейной регрессии, in_features - кол-во входящих переменных, out_features - кол-во исходящих значений. В функции Y = F(X) это размерность входного и получаемого тензоров.
WibeCoding
Сделай мне профессиональный промпт для разработки геймифицированного квиза для финансового советника,
он должен вовлекать и определять уровень финансовой грамотности а после призыв на бесплатную 20-минутную
консультацию по финансам, потом я задеплою на хостинге и настрою яндекс директ на этот квиз. Ссылка
на сайт откуда брать информацию - ...Практика.
Создать git проекта