k8s
- Тестовый kubernetes
- Сетевая подсистема
- Pod & containers
- Namespaces
- Deployment
- Services
- Ingress
- Storages
- Config maps & secrets
- StatefulSet
- Безопасность
- Job, cronjob
Тестовый kubernetes
Интересная статья по настройке HA k8s
Docker desktop
Введение.
Для изучения kubernetes в книге "The kubernetes book 2024 edition" автора Nigel Poulton предложено использовать Docker Desktop для запуска одноузлового кластера и дальнейших экспериментов. Я решил не устанавливать лишнего в систему и запустить все на виртуальной машине. Итоговый стек: Windows 10 - Virtualbox 7.0 - Ubuntu 24.04 - Docker Desktop - K8s.
Настройки VM:
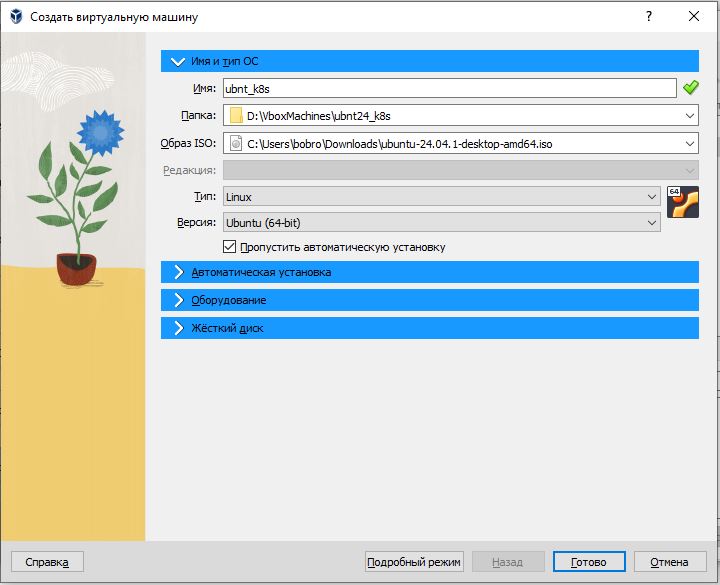
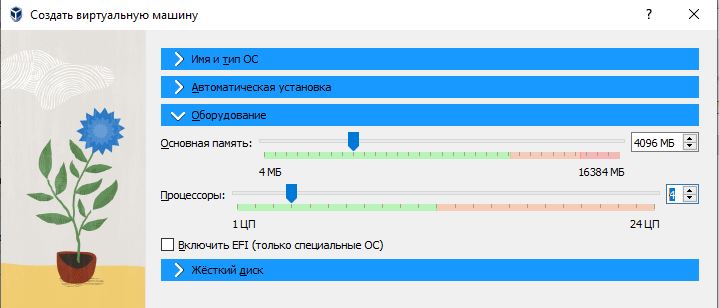
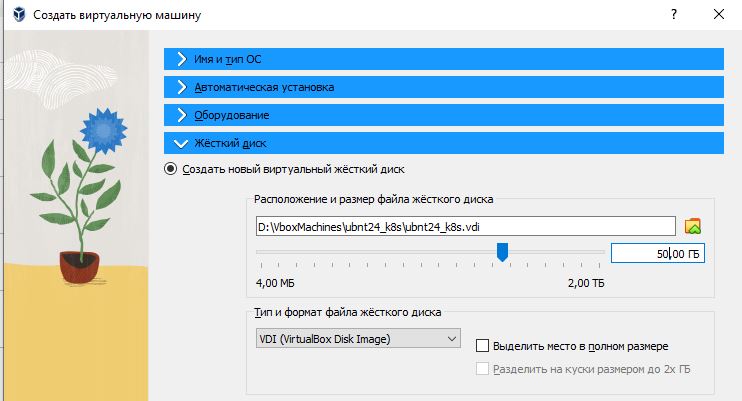
Установка
mkdir -p $HOME/.kube
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.31/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.31/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
sudo systemctl enable --now kubelet
swapoff -a
kubectl
kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.0.109
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get nodes
kubeadm token create --print-join-command
kubectl get nodes
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
kubectl get no
kubectl get po --all-namespacesДополнительные удобства
Настройка другого редактора (по умолчанию vi) например при выполнении команды kubectl edit pod ...
nano .bashrc
#Добавить строку
export EDITOR=nano
#Для использования в текущей сессии, в последующих сессиях автоматически
source ~/.bashrcПри установке через kubeadm для балансировки трафика требуется MetalLB, детали установки
Установка kubectl для управления с другой системы
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectlСкопировать файл авторизации config в ~/.kube/config
Сетевая подсистема
Стартовая информация
Сетевой плагин выбирается во время установки кластера.
Документация, сетевая модель K8s Выдержки:
- Сетевая подсистема используется только подами (не нодами).
- У каждой node свой пул ip адресов для запущенных у них pod.
- Каждый Pod в кластере имеет собственный уникальный в пределах кластера IP адрес.
- У каждого Pod свое частное сетевое пространство, общее для всех контейнеров внутри Pod. Контейнеры внутри Pod взаимодействуют через localhost.
- Pod'ы взаимодействуют с Pod на других нодах при помощи сетевого плагина (CNI).
- Служба - это метод предоставления доступа к Pod в кластере (внутренний и внешний)
Вот вроде просто, но нихера не понятно. Поэтому дальше начинается самое веселое)
Следствия пункта 1. Связность между нодами и контроллером опосредованно зависит от сетевого взаимодействия подов. Поэтому вопрос сети при управлении - один вопрос, вопрос сети подов - второй вопрос.
Первый вопрос относительно простой: сетевая видимость точка - точка между IP адресами. Необходимые порты при настройке port-forwarding:
На мастер нодах:
TCP 6443* Kubernetes API Server
TCP 2379-2380 etcd server client API
TCP 10250 Kubelet API
TCP 10251 kube-scheduler
TCP 10252 kube-controller-manager
TCP 10255 Read-Only Kubelet APIНа воркерах:
TCP 10250 Kubelet API
TCP 10255 Read-Only Kubelet API
TCP 30000-32767 NodePort ServicesОткрываем порты и управление начнет работать. Теперь нужна сетевая связность между подами.

Для использования службы типа LoadBalancer необходимо установить балансировщик, например MetalLB. При существовании кластера в пределах одного L2 сегмента хватит L2 режима. Однако при разных сетях у worker потребуется BGP. Картинку можно представить следующим образом:

Роли маршрутизаторов R1 и R2 выполняют сетевые плагины (MetalLB, Calico, ...) в BGP режиме. Им необходим обмен маршрутной информацией в пределах L3 сети. Классическая сетевая задача - сделать видимым IP Pool 1 для IP Pool 2. Тут можно решить при помощи VXLAN и т д. В случае реализации без туннелей в L3 сети требуется, чтобы маршрутизаторы внутри этой сети также обладали маршрутной информацией.
Настройка MetalLB
Примените манифест для установки MetalLB
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.7/config/manifests/metallb-native.yamlДождаться запуска контейнеров
kubectl get pods -n metallb-systemСоздайте конфигурационный файл для MetalLB. Например, metallb-config.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: first-pool
namespace: metallb-system
spec:
addresses:
- 192.168.1.240-192.168.1.250 # Укажите диапазон IP-адресов, доступных в вашей сети
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: l2advert
namespace: metallb-system
spec:
ipAddressPools:
- first-poolПрименить конфигурацию:
kubectl apply -f metallb-config.yamlPod & containers
Pod (под)
Pod это уровень абстракции. Он включает:
- совместное использование ресурсов
- управление планировщиком
- тестирование на рабочеспособность
- политики перезапуска
- политики безопасности
- контроль завершения
- тома
Он также абстрагирует детали рабочей нагрузки (контейнер, виртуальная машина, Wasm) но для некоторых могут потребоваться дополнительные модули (например KubeVirt для виртуалок).
Под смертен (после завершения или ошибки он удаляется без возможности перезапуска) и постоянны (для изменения нужно удалить старый и создать новый).
Настройка ноды для пода
NodeSelectors - список меток нодов. Простейший случай.
Affinity and anti-affinity - продвинутый способ Позволяет
attract
• Anti-affinity rules repel
• Hard rules must be obeyed
• Soft rules are only suggestions
Topology spread constraints - ограничения на топологию
Resource requests and resource limits
Теория процесса запуска pod
- Создать YAML манифест
- Отправить манифест на API сервер
- Запрос будет аутентифицирован и авторизован
- Спецификация будет проверена
- Планировщик отфильтрует ноды на основе ограничений
- Под будет привязан к удовлетворяющей требованиям ноде
- Сервис kubelet на ноде получит задание
- Сервис kubelet скачает спецификацию и сформирует задачу для исполнения
- Сервис kubelet мониторит статус поды и в случае изменения направляет информацию на планировщик
Запуск пода
Есть два варианта: непосредственно через манифест на ноде или через контроллер. Первый вариант быстрый но без большинства возможностей (статический под, типа docker container). Второй вариант используется обычно.
Кластер создает сеть подов и автоматически подключает все поды к ней. Это одноуровневая L2 overlay сеть
Статусы пода
Pending под еще не создан, поиск ноды для запуска
Running нода найдена, запуск произведен
Init:X/Y исполнение инит контейнеров, завершено X из Y
Политики перезапуска настраиваются для контейнера. Поэтому пока идет перезапуск контейнера, считается что под еще работает. При обновлении под удаляется и создается новый. Это необходимо учитывать при разработке архитектуры.
Структура YAML файла
Верхний уровень
| Параметр | Описание |
| Kind |
Тип определяемого объекта. В данном случае Pod |
| apiVersion |
Версия API |
| metadata |
Метаданные |
| spec |
Спецификация контейнеров |
Metadata: метаданные пода
| Параметр | Описание |
| name |
Имя пода. Используется в качестве hostname у всех контейнеров для этого пода. Поэтому должно быть валидным DNS именем |
| labels |
Метки пода |
Spec: описание параметров контейнера, томов, внутри для каждого контейнера - name: имя_контейнера
| Параметр | Описание |
| containers |
Обычные контейнеры |
| initContainers |
Контейнеры, запускаемые до старта обычных контейнеров. Обычные запускаются только после завершения init контейнеров. |
| volumes: |
Тома |
Параметры контейнера:
| Параметр | Описание |
| image |
Образ Для использования другого хаба добавить URL перед именем образа
|
| ports |
Порты |
| resources |
ограничения на ресурсы Если нода с нужными ресурсами не найдена - под в статусе Pending. Для всех контейнеров в поде. |
| env |
Переменные окружения. |
| volumeMounts |
Тома Настройки тома проводятся отдельно |
Пример 1.
kind: Pod
apiVersion: v1
metadata:
name: hello-pod
labels:
zone: prod
version: v1
spec:
containers:
- name: hello-ctr
image: nigelpoulton/k8sbook:1.0
ports:
- containerPort: 8080
resources:
limits:
memory: 128Mi
cpu: 0.5Пример 2. Init контейнер.
apiVersion: v1
kind: Pod
metadata:
name: initpod
labels:
app: initializer
spec:
initContainers:
- name: init-ctr
# Pinned to 1.28 as newer versions have a sketchy nslookup command that doesn't work. Can also use a non-busybox image here
image: busybox:1.28.4
command: ['sh', '-c', 'until nslookup k8sbook; do echo waiting for k8sbook service; sleep 1; done; echo Service found!']
containers:
- name: web-ctr
image: nigelpoulton/web-app:1.0
ports:
- containerPort: 8080Пока образы в init контейнере не завершились, статус в Init:0/1
kubectl get pods --watch
NAME READY STATUS RESTARTS AGE
initpod 0/1 Init:0/1 0 16sПример 3. Дополнительный контейнер, обновляющий папку при изменении репозитория
# Some network drivers and laptop VM implementations cause issues with Service port mapping
# Minikube users may have to `minikube service svc-sidecar` to be able to access on `localhost:30001`
# Other users may have to run `kubectl port-forward service/svc-sidecar 30001:80`
apiVersion: v1
kind: Pod
metadata:
name: git-sync
labels:
app: sidecar
spec:
containers:
- name: ctr-web
image: nginx
volumeMounts:
- name: html
mountPath: /usr/share/nginx/
- name: ctr-sync
image: k8s.gcr.io/git-sync:v3.1.6
volumeMounts:
- name: html
mountPath: /tmp/git
env:
- name: GIT_SYNC_REPO
value: https://gitverse.ru/bobrobot/k8s_pods.git
- name: GIT_SYNC_BRANCH
value: master
- name: GIT_SYNC_DEPTH
value: "1"
- name: GIT_SYNC_DEST
value: "html"
volumes:
- name: html
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: svc-sidecar
spec:
selector:
app: sidecar
type: NodePort
ports:
- port: 80
nodePort: 30001При обращении на адрес кластера или ноды будет отображаться страница.
Основные команды
| Команда | Доп. пар. | Описание |
| kubectl explain pods --recursive | Вывод всех параметров, доступных для конфигурирования Pod | |
| kubectl get pods | список контейнеров | |
| -o yaml | расширенная информация о подах | |
| kubectl apply | -f file.yml | Создание под из file.yml |
| kubectl describe | pod pod_name | Описание пода |
| kubectl logs pod_name | логи на поде. По умолчанию первого контейнера в поде | |
| --container cont_name | логи конкретного контейнера | |
| kubectl exec | Выполнение команд внутри контейнера Два варианта | |
| pod_name -- command | Выполняет command на pod_name и возвращает результат в консоль. По умолчанию на первом контейнере. -- container для указания контейнера. | |
| -it pod_name -- command | Подключается в интерактивном режиме на контейнер и выполняет команду.
|
|
| kubectl edit pod pod_name | Редактирование под (для nano - в части дополнительные удобства Тестовый k8s) Пока не получилось. | |
| kubectl delete | pod | Удаление подов. Имена подов через пробел |
| svc | Удаление сервисов. | |
| -f | Удаление с использованием yaml файлов. |
Container (контейнер)
Паттерны мультиконтейнеров
Init контейнеры - специальный тип контейнеров, для которых K8s гарантирует единственный запуск и завершение, перед остальными контейнерами. Пример: есть приложение и внешнее API с которым обязательно должно быть взаимодействие при старте. Вместо нагрузки на основную логику, можно процесс проверки вывести в init контейнер.
Slidecar контейнеры - выполняют периферийные задачи. Пока что бета.
Namespaces
Разделяет кластер на виртуальные кластеры. Это не Namespace ядра! По умолчанию объекты попадают в default namespace. Настраиваются свои пользователи, права, ресурсы и политики.
Создание и привязка к пространству имен
Императивный способ:
kubectl create ns hydraДекларативный способ: создать yaml файл и применить его.
Для привязки объекта к пространству имен в метаданных нужно указать namespace
apiVersion: v1
kind: ServiceAccount
metadata:
namespace: shield <<==== Namespace
name: defaultСтруктура YAML файла
Верхний уровень
| Параметр | Описание |
| Kind |
Тип определяемого объекта, Namespace |
| apiVersion |
Версия API |
| metadata |
Метаданные |
Metadata
| Параметр | Описание |
| name | Имя |
| labels | метки |
Примеры
kind: Namespace
apiVersion: v1
metadata:
name: shield
labels:
env: marvelОсновные команды
| Команда | Доп. пар. | Описание |
| kubectl api-resources | Список API ресурсов, в частности - делятся ли на namespace | |
| kubectl get namespaces | Список пространств имен | |
| kubectl describe ns name_ns | Информация по name_ns пространству имен | |
| Все команды получения информации | --namespace default | Фильтрация по определенному namespace |
| --all-namespaces | Для всех namespace | |
| kubectl create ns ns_name | Создание пространства имен ns_name | |
| kubectl delete ns ns_name | Удаление пространства имен ns_name | |
| kubectl config set-context --current --namespace shield | Установка пространства имен по умолчанию |
Deployment
Deployments наиболее популярный способ для запуска приложений без сохранения состояния. Это добавляет проверку состояния, масштабирование, восстановление.
Реализовано через deployment контроллер. Каждый контроллер управляет одним или несколькими одинаковыми подами.
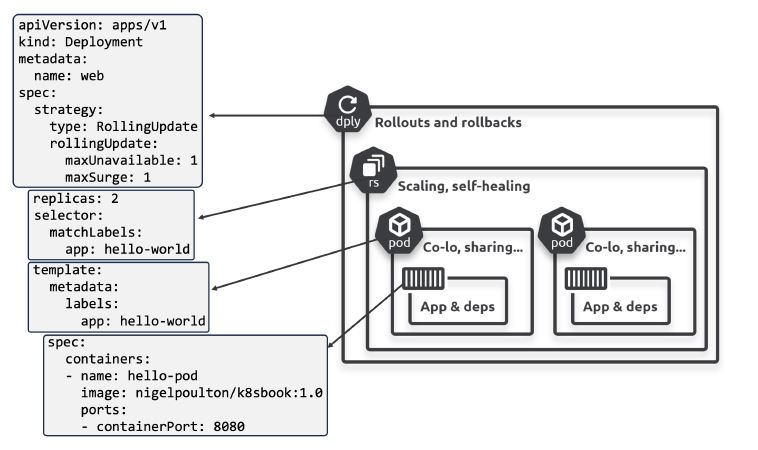
Масштабирование (Scalling)
Существуют несколько типов
| Тип | Описание |
| Horizontal Pod Autoscaler | Масштабирование количества подов, наиболее часто используется. |
| Vertical Pod Autoscaler | Масштабирование ресурсов, потребляемых подами. Не установлен по умолчанию. Редко используется |
| Cluster Autoscaler | Добавляет/удаляет ноды. По умолчанию, часто используется. |
Например, указываем кол-во подов от 2 до 10. Нагрузка повысилась, и HPA запрашивает еще 2 пода. Они запускаются. Но нагрузка растет, и запрашивается еще 2 пода. Однако на существующем кластере нет возможности запустить еще 2 пода, и они переходят в статус Pending. CA определяет Pending поды и увеличивает количество нодов, запуская там поды. И наоборот.
Масштабирование связано с понятием текущего состояния (state). Есть необходимое состояние и наблюдаемое состояние. При неравенстве контроллер запускает процесс изменений.
Важно: архитектура приложения должна поддерживать возможность масштабирования. Микросервисы должны взаимодействовать только через API. При увеличении количества, добавляется новый под.
Реплики
ReplicaSets - набор настроек и подов с одной версией конфигурации. При обновлении yaml создается вторая ReplicaSet и один новый под. Из старой ReplicaSet удаляется один под. И так далее до полного обновления. Но конфигурация сохраняется. Можно вернуть к старым настройкам.
Структура YAML файла
Верхний уровень
| Параметр | Описание |
| kind | Тип, в данном случае Deployments |
| spec | Спецификация |
spec
| Параметр | Описание |
| strategy | Стратегия восстановления |
| replicas | кол-во реплик |
| selector | правила выбора меток |
| template | описание шаблона (все аналогично описанию пода) |
Примеры
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-deploy
spec:
replicas: 10
selector:
matchLabels:
app: hello-world
revisionHistoryLimit: 5
progressDeadlineSeconds: 300
minReadySeconds: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-pod
image: nigelpoulton/k8sbook:1.0
ports:
- containerPort: 8080
resources:
limits:
memory: 128Mi
cpu: 0.1Пример сервиса для данного приложения
apiVersion: v1
kind: Service
metadata:
name: lb-svc
labels:
app: hello-world
spec:
type: LoadBalancer
ports:
- port: 8080
protocol: TCP
selector:
app: hello-worldОсновные команды
| Команда | Доп. пар. | Описание |
| kubectl get deploy dep_name | статус | |
| kubectl describe deploy dep-name | Расширенная информация | |
| kubectl get rs | Список реплик | |
| kubectl scale | deploy dep_name --replicas count | Императивное масштабирование. Нежелательно. |
| kubectl rollout status deployment dep_name | Статус обновления подов | |
| kubectl rollout pause deploy dep_name | Приостановка обновления | |
| kubectl describe deploy dep_name | Отображает в частности список роллбеков | |
| kubectl rollout history deployment dep_name | История роллбеков | |
| kubectl rollout undo deployment hello-deploy --to-revision=1 | Возврат. Быстро, но не рекомендуется. Лучше через загрузку старого файла из репозитория и обновление. |
Services
Сервис используется для подключения подов к внешней сети. Сервис использует метки для выбора подов. Все указанные метки должны быть на поде (дополнительные метки пода игнорируются)
В сервисе - раздел selector
spec:
replicas: 10
<Snip>
template:
metadata:
labels:
project: tkb
zone: prod
<Snip>
---
apiVersion: v1
kind: Service
metadata:
name: tkb
spec:
ports:
- port: 8080
selector:
project: tkb
zone: prod Типы сервисов
ClusterIP Используется для доступности подов внутри кластера. Доступность по имени сервиса.
NodePort Services Используется для доступа приложений снаружи кластера. Добавляет указанный порт на каждую ноду.
apiVersion: v1
kind: Service
metadata:
name: skippy <<==== Registered with the internal cluster DNS (ClusterIP)
spec:
type: NodePort <<==== Service type
ports:
- port: 8080 <<==== ClusterIP port
targetPort: 9000 <<==== Application port in container
nodePort: 30050 <<==== External port on every cluster node (NodePort)
selector:
app: hello-worldВ данном примере изнутри под доступен по порту 8080, снаружи - по порту 30050. Диапазон портов 30000-32767.
LoadBalancer Services Используется для сервисов со стартовым диапазоном портов, наиболее часто.
apiVersion: v1
kind: Service
metadata:
name: lb <<==== Registered with cluster DNS
spec:
type: LoadBalancer
ports:
- port: 8080 <<==== Load balancer port
targetPort: 9000 <<==== Application port inside container
selector:
project: tkbМой кубер использует flannel, а для корректной работы LoadBalancer нужен балансировщик, например MetalLB. Стек в случае балансировщика:
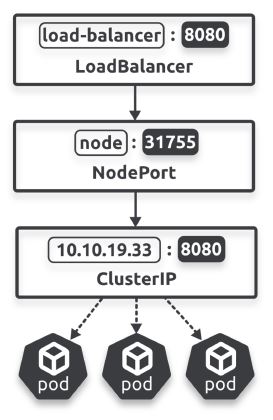
Headless сервисы
Сервисы без IP адреса. Их цель - создать DNS записи для StatefulSet подов. Клиенты запрашивают DNS имена подов и направляют непосредственно им запросы вместо использования кластерного IP. Пример сервиса:
apiVersion: v1
kind: Service <<==== Normal Kubernetes Service
metadata:
name: dullahan
labels:
app: web
spec:
ports:
- port: 80
name: web
clusterIP: None <<==== Make this a headless Service
selector:
app: web
Структура YAML файла
Верхний уровень
| Параметр | Описание |
| kind | Тип, в данном случае Service |
| spec | Спецификация |
spec
| Параметр | Описание |
| type | тип (ClusterIP, NodePort, LoadBalancer) |
| ports |
port - порт фронтенда targetPort - порт на бэке |
| selector | правила выбора меток |
Пример yaml файла
apiVersion: v1
kind: Service
metadata:
name: cloud-lb
spec:
type: LoadBalancer
ports:
- port: 9000
targetPort: 8080
selector:
chapter: servicesОсновные команды
| Команда | Доп. пар. | Описание |
| kubectl expose deployment dep_name --type=LoadBalancer | Ручное создание сервиса. Вот только не поехало. | |
| kubectl get svc -o wide | Информация по сервисам | |
| kubectl get endpointslices | Список ендпоинтов | |
| kubectl describe endpointslice epname | Описание ендпоинта |
Ingress
Используется для организации внешнего взаимодействия на L7 уровне. Ingress ресурсы определяют правила маршрутизации, Ingress контроллер выполняет задачу.
Маршрутизация в смысле L7, не в смысле L3
Могут быть host-based и path-based маршруты:
| Host-based example | Path-based example | Backend K8s Service |
| shield.mcu.com | mcu.com/shield | shield |
| hydra.mcu.com | mcu.com/hydra | hydra |
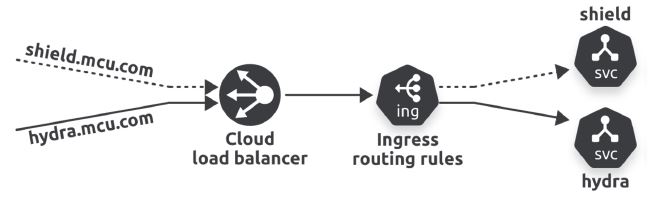
Необходим внешний Ingress-controller, очень часто Nginx.
Ingress классы
Позволяют запустить несколько ingress контроллеров в одном кластере. Сначала привязывается Ingress контроллер к классу, затем при создании объект Ingress привязывается к классу.
Пример
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: mcu-all
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: shield.mcu.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-shield
port:
number: 8080
- host: mcu.com
http:
paths:
- path: /shield
pathType: Prefix
backend:
service:
name: svc-shield
port:
number: 8080Основные команды
| Команда | Доп. пар. | Описание |
| kubectl get ingressclass | Список классов Ingress | |
| kubectl describe ingressclass class_name | Детализация для класса class_name | |
| kubectl get ingress my-ingress -n my-ns -o yaml | Получить конфигурацию в виде yaml | |
| kubectl get ing | Список ingress | |
| kubectl describe ing mcu-all | Детализация ingress |
Storages
Система хранения работает через драйверы (CSI плагины) или локально на нодах. Второй вариант неудобный. Далее первый вариант. Разработчик обычно предоставляет плагины в виде Helm чартов или yaml установщиков. Они устанавливаются в виде набора подов в namespace kube-system. Список плагинов Для тестов можно использовать встроенный драйвер, OpenEbs. К вопросу выбора драйвера, архитектуры хранилища и безопасности необходимо подходить очень серьезно.
Процесс запроса ресурсов: Pod Volume - PVC - SC - CSI Plugin
Storage Classes
ресурсы в storage.k8s.io/v1 группе. Неизменяемый. Для обновления нужно удалить и создать. SC access mode:
- ReadWriteOnce - один PVC может подключиться в режиме чтения/записи
- ReadWriteMany - несколько PVC. Файловые и объектные хранилища обычно поддерживают, блоковые нет.
- ReadOnlyMany - несколько PVC в режиме чтения.
Все PV должны подключиться в одинаковом режиме.
Reclaim policy (политика восстановления)
Политики восстановления сообщают Kubernetes, что делать с PV и связанным с ним внешним хранилищем, когда его PVC будет запущен.
- Delete. Удаление PVC приведет к удалению PV и внешнего хранилища.
- Retain. Безопаснее, но нужно самостоятельно удалять ресурсы.
Volume binding mode
Момент создания бакета. Immediate - сразу же, WaitForFirstConsumer - при подключении первого.
Примеры
Локальное хранилище (устаревшее)
На воркере
sudo mkdir -p /mnt/disks/ssd1
sudo chmod 777 /mnt/disks/ssd1 # Для упрощения примераНастройка PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
labels:
type: local
spec:
capacity:
storage: 10Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- <node-name> # Замените на имя узла, где находится директорияНастройка PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: example-local-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: local-storage
resources:
requests:
storage: 10GiПроверка связи
kubectl get pv
kubectl get pvcИспользование в Pod
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: local-storage
volumes:
- name: local-storage
persistentVolumeClaim:
claimName: example-local-pvcУдаление ресурсов
kubectl delete pod example-pod
kubectl delete pvc example-local-pvc
kubectl delete pv example-local-pvХранилище Yandex.cloud
S3 aws - совместимое хранилище.
1. Настройка доступа через консоль
Установить консоль yc
curl -sSL https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bash
source ~/.bashrcЗапросить новый OAuth токен. Время жизни токена 1 год.
Инициализировать консоль
yc init2. Настройка доступа к бакету
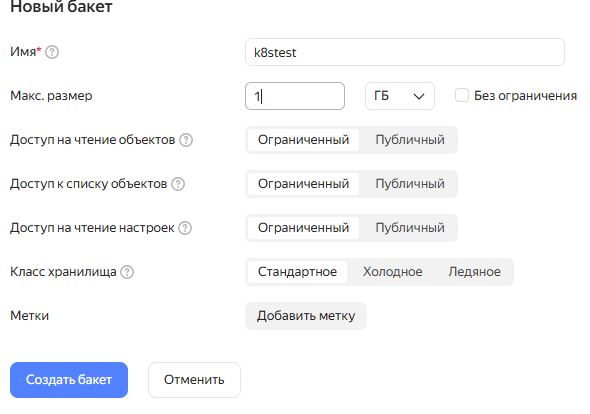
Через web-консоль создать бакет.
Выяснить folder_id созданного аккаунта
yc storage bucket get k8stest
name: k8stest
folder_id: b...q
anonymous_access_flags:
read: false
list: false
config_read: false
default_storage_class: STANDARD
versioning: VERSIONING_DISABLED
max_size: "1073741824"
created_at: "2025-03-23T06:35:58.715069Z"Создать сервисный аккаунт для доступа к бакету, в выводе будет id аккаунта
yc iam service-account create --name k8stest --output key.jsonФайл key.json понадобится далее.
Добавить роль для созданного бакета сервис аккаунту
yc resource-manager folder add-access-binding <идентификатор_каталога> \
--role <роль> \
--subject serviceAccount:<идентификатор_сервисного_аккаунта>3. Установка CSI плагина для yandex.cloud
git clone https://github.com/deckhouse/yandex-csi-driver.git
cd yandex-csi-driverВ самом git сказано, что запускать нужно из папки deploy/1.17 установив 2 переменные. У меня это не заработало.
В папке yandex-csi-driver/charts/yandex-csi-controller установить serviceAccountJSON и folderID
В файле csidriver.yaml заменить apiVersion: storage.k8s.io/v1beta1 на apiVersion: storage.k8s.io/v1
Дополнительно:
# Список сервис аккаунтов
yc iam service-account list
# Детализация информации по аккаунту
yc iam service-account get <идентификатор_аккаунта>
# Удаление аккаунта
yc iam service-account delete <идентификатор_аккаунта>И нечего с yandex не получилось.
Настройка MinIO
Настройка авторизации
Создать Secret. Ключ и Секрет не в Base64, а как указано при создании бакета.
apiVersion: v1
kind: Secret
metadata:
namespace: kube-system
name: csi-s3-secret
stringData:
accessKeyID: XP5...Ih
secretAccessKey: klz...zo
# For AWS set it to "https://s3.<region>.amazonaws.com"
endpoint: http://192.168.1.194:9000
# If not on S3, set it to ""
region: ""
Применить Secret
kubectl apply -f 1-minio-credentials.yaml
kubectl get secretУстановка csi драйвера
Проверить установленные csi драйверы, поставить драйвер
git clone https://github.com/ctrox/csi-s3.git
cd csi-s3/deploy/kubernetes
kubectl apply -f .Вот только какого-то хера в данной директории не было yaml для создания драйвера) Добавляем драйвер
apiVersion: storage.k8s.io/v1
kind: CSIDriver
metadata:
name: ch.ctrox.csi.s3-driver
spec:
attachRequired: false
podInfoOnMount: true
Обязательно в списке драйверов должен появиться драйвер
kubectl get csidrivers.storage.k8s.io
NAME ATTACHREQUIRED PODINFOONMOUNT TOKENREQUESTS REQUIRESREPUBLISH MODES AGE
ch.ctrox.csi.s3-driver false true <unset> false Persistent 36m
И все поды csi должны быть запущены
kubectl --namespace kube-system get pods | grep csi
csi-attacher-s3-0 1/1 Running 0 9h
csi-provisioner-s3-0 2/2 Running 0 9h
csi-s3-f5v74 2/2 Running 0 9hНастройка класса и PVC
Добавляем StorageClass
---
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: csi-s3
provisioner: ch.ctrox.csi.s3-driver
parameters:
# specify which mounter to use
# can be set to rclone, s3fs, goofys or s3backer
#mounter: rclone
mounter: "s3fs"
otherOpts: "-o allow_other -o uid=0 -o gid=0 -o umask=000"
# to use an existing bucket, specify it here:
bucket: bucketone
path: "pvc-fbd999ab-1ba7-4b07-922d-51270e6028d9"
csi.storage.k8s.io/provisioner-secret-name: csi-s3-secret
csi.storage.k8s.io/provisioner-secret-namespace: kube-system
csi.storage.k8s.io/controller-publish-secret-name: csi-s3-secret
csi.storage.k8s.io/controller-publish-secret-namespace: kube-system
csi.storage.k8s.io/node-stage-secret-name: csi-s3-secret
csi.storage.k8s.io/node-stage-secret-namespace: kube-system
csi.storage.k8s.io/node-publish-secret-name: csi-s3-secret
csi.storage.k8s.io/node-publish-secret-namespace: kube-system
sslVerify: "false"
reclaimPolicy: Retain
volumeBindingMode: Immediate
mounter rclone на финальном этапе отказался создавать файлы.
В директории бакета была создана директория pvc-fbd999ab-1ba7-4b07-922d-51270e6028d9/csi-fs Не знаю почему. но при команде ls (проверка) он находился внутри нее.
Добавляем PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: csi-s3-pvc
namespace: default
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: csi-s3
Проверка:
apiVersion: v1
kind: Pod
metadata:
name: minio-test-pod
spec:
containers:
- name: app
image: alpine
command: ["sleep", "infinity"]
volumeMounts:
- name: minio-storage
mountPath: /mnt/minio
volumes:
- name: minio-storage
persistentVolumeClaim:
claimName: csi-s3-pvc
readOnly: false
Команда
kubectl exec -it minio-test-pod -- sh -c "echo 'New test' > /mnt/minio/test2.txt && ls /mnt/minio"должна вывести созданный файл в списке.
Основные команды
| Команда | Доп. пар. | Описание |
| kubectl get csidrivers.storage.k8s.io | Список CSI-драйверов | |
| kubectl get storageclass -o wide | Какой PROVISIONER используется | |
| kubectl get pods -n kube-system | grep csi | Поды CSI-драйверов. Какие поды отвечают за CSI | |
| kubectl get daemonsets -n kube-system | Где работает CSI-драйвер |
Config maps & secrets
Набор конфигураций для различных окружений. Включают переменные окружения, конфиг файлы, имена хостов, порты, аккаунты.
kind: ConfigMap
apiVersion: v1
metadata:
name: epl
data:
Competition: epl
Season: 2022-2023
Champions: Manchester City
test.conf: |
env = plex-test
endpoint = 0.0.0.0:31001
char = utf8
vault = PLEX/test
log-size = 512MИх можно использовать как переменные окружения, параметры запуска и файлы внутри контейнера.
Использование ConfigMap
В виде переменных окружения:
apiVersion: v1
kind: Pod
<Snip>
spec:
containers:
- name: ctr1
env:
- name: FIRSTNAME
valueFrom:
configMapKeyRef: <<==== a ConfigMap
name: multimap <<==== called "multimap"
key: givenНе изменяются после создания.
В виде аргументов:
Сначала как переменные окружения, затем в команду создания
spec:
containers:
- name: args1
image: busybox
env:
- name: FIRSTNAME <<==== Environment variable called FIRSTNAME
valueFrom: <<==== based on
configMapKeyRef: <<==== a ConfigMap
name: multimap <<==== called "multimap"
key: given <<==== and populated by the value in the "given" field
- name: LASTNAME <<==== Environment variable called LASTNAME
valueFrom: <<==== based on
configMapKeyRef: <<==== a ConfigMap
name: multimap <<==== called "multimap"
key: family <<==== and populated by the value in the "family" field
command: [ "/bin/sh", "-c", "echo First name $(FIRSTNAME) last name $(LASTNAME)" ]
В виде файлов:
Создается том и привязывается к нему ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: cmvol
spec:
volumes:
- name: volmap <<==== Create a volume called "volmap"
configMap: <<==== based on the ConfigMap
name: multimap <<==== called "multimap"
containers:
- name: ctr
image: nginx
volumeMounts: <<==== These lines mount the
- name: volmap <<==== the "volmap" volume into the
mountPath: /etc/name <<==== container at "/etc/name"
Файлы будут созданы в соответствии именам в ConfigMap. При обновлении ConfigMap файлы в контейнере обновятся.
Secrets
Хранятся в Base64 но внутри контейнера хранятся в tmpfs виде обычного текста.
apiVersion: v1
kind: Secret
metadata:
name: tkb-secret
labels:
chapter: configmaps
type: Opaque
data: <<==== Change to "stringData" for plain text
username: bmlnZWxwb3VsdG9u
password: UGFzc3dvcmQxMjM=
Использование в Pod:
apiVersion: v1
kind: Pod
metadata:
name: secret-pod
labels:
topic: secrets
spec:
volumes:
- name: secret-vol <<==== Volume name
secret: <<==== Volume type
secretName: tkb-secret <<==== Populate volume with this Secret
containers:
- name: secret-ctr
image: nginx
volumeMounts:
- name: secret-vol <<==== Mount the volume defined above
mountPath: "/etc/tkb" <<==== into this pathВ директории /etc/tkb будут храниться файлы, по одному на каждое значение.
Основные команды
| Команда | Доп. пар. | Описание |
| kubectl get cm | Список ConfigMap |
StatefulSet
Очень похожи на Deployments, но StatefulSet дополнительные функции:
- Предсказуемые и постоянные имена модулей
- Предсказуемые и постоянные имена узлов DNS
- Предсказуемые и постоянные привязки томов
Отличие: Deployment создает поды сразу же, а StatefulSet по одному. Это критично для сохранения данных.
Именование подов: <StatefulSet name>-<integer>. Число от 0-...
Для каждого пода создается свой том, с соответствующим именованием. Созданные тома имеют свой жизненный цикл и они не удаляются при масштабировании подов.
Удаление Statefulset: Автоматического удаления подов нет. Сначала нужно снизить количество до 0. Также нужно использовать terminationGracePeriodSeconds около 10 секунд для безопасного завершения работы.
Создаем headless сервис (Services)
Безопасность
Авторизация и аутентификация
По умолчанию аутентификация на основе сертификата, но поддерживаются внешние источники.
Аутентификация на основе сертификата.
Авторизация RBAC (пользователь - действие - ресурс). По умолчанию запрещено все что не разрешено. Роли определяют правила, RoleBindings определяют принадлежность пользователей к ролям. Пример настройки ролей:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: shield
name: read-deployments
rules:
- verbs: ["get", "watch", "list"] <<==== Allowed actions
apiGroups: ["apps"] <<==== on resources
resources: ["deployments"] <<==== of this typeПример RoleBinding:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-deployments
namespace: shield
subjects:
- kind: User
name: sky <<==== Name of the authenticated user
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: read-deployments <<==== This is the Role to bind to the user
apiGroup: rbac.authorization.k8s.ioСвойства правил роли:
verbs ["get", "watch", "list", "create", "update", "patch", "delete"]
ApiGroups (в пределах namespace):
| apiGroup | Ресурс |
| "" | pods, secrets |
| “storage.k8s.io” | storageclass |
| “apps” | deployments |
Полный список API ресурсов:
kubectl api-resources --sort-by name -o wideМожно использовать звездочку.
Все роли используются только в контексте namespace!
Кластерные роли и привязки
ClusterRoleBindings используется для создания шаблонов ролей и привязки их к конкретным ролям.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole <<==== Cluster-scoped role
metadata:
name: read-deployments
rules:
- verbs: ["get", "watch", "list"]
apiGroups: ["apps"]
resources: ["deployments"]
Пользователи
Интересная статья Еще одна, тоже стоит почитать
Обычных пользователей нельзя добавить через вызовы API. Возможные варианты:
- Базовая аутентификация (basic auth):
- передача конфигурации API-серверу со следующим (или похожим) содержимым: password, username, uid, group;
- Клиентский сертификат X.509:
- создание секретного ключа пользователя и запроса на подпись сертификата;
- заверение его в центре сертификации (Kubernetes CA) для получения сертификата пользователя;
- Bearer-токены (JSON Web Tokens, JWT):
- OpenID Connect;
- слой аутентификации поверх OAuth 2.0;
- веб-хуки (webhooks).
Структура файла ~/.kube/config
- Clusters - список кластеров. Сертификат кластера, адрес и внутреннее имя
- Users - пользователи. Внутреннее имя, сертификат и ключ
- Contexts - объединение пользователя и кластера. Внутреннее имя, внутреннее имя кластера и внутреннее имя пользователя
- Current-context - имя текущего контекста
Важный момент: кубер не управляет членством пользователей в группах. Получить напрямую доступ к спискам пользователей в группе нельзя.
Пример создания пользователя с авторизацией через X.509 сертификат.
Создаем директорию хранения информации о пользователях и генерируем в нее ключ
mkdir -p users/sergey/.certs
openssl genrsa -out ~/users/sergey/.certs/sergey.key 2048Генерируем запрос на сертификат
openssl req -new -key ~/users/sergey/.certs/sergey.key -out ~/users/sergey/.certs/sergey.csr -subj "/CN=sergey/O=testgroup"Обработка запроса на сертификат
openssl x509 -req -in ~/users/sergey/.certs/sergey.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out ~/users/sergey/.certs/sergey.crt -days 500В некоторых ресурсах говорится, что команда kubectl config set-credentials ... создает пользователя в кластере Kubernetes. Но это не так, команда kubectl config ... создает/модифицирует файл .kube/config, поэтому нужно быть осторожным и не побить свой файл. А Kubernetes авторизует всех пользователей, чей сертификат подписан его центром сертификации.
Добавляем пользователя sergey
kubectl config set-credentials sergey \
--client-certificate=/root/users/sergey/.certs/sergey.crt \
--client-key=/root/users/sergey/.certs/sergey.key \
--embed-certs=trueЕсли нужно - создали бы настройки кластера, но у нас есть, поэтому создаем контекст с существующим кластером. Namespace, если нужно, указывается в настройках контекста.
kubectl config set-context sergey-context --cluster=kubernetes --user=sergey --namespace=sergey-nsТеперь осталось пользователю определить права.
Например определим роль sergey-ns-full с полным доступом к namespace sergey-ns
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: sergey-ns-full
namespace: sergey-ns
rules:
- apiGroups: [ "*" ]
resources: [ "*" ]
verbs: [ "*" ]Сейчас вместо привязки пользователя, привяжем группу к роли.
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: testgroup-rolebinding # Название RoleBinding
namespace: sergey-ns # Namespace, где применяется
subjects:
- kind: Group # Тип субъекта — группа
name: testgroup # Название группы
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role # Тип привязываемой роли (Role или ClusterRole)
name: sergey-ns-full # Название роли
apiGroup: rbac.authorization.k8s.ioПереключаемся на контекст и проверяем
kubectl config use-context sergey-contextСоздаем простой под
kind: Pod
apiVersion: v1
metadata:
name: hello-pod
labels:
zone: prod
version: v1
spec:
containers:
- name: hello-ctr
image: nigelpoulton/k8sbook:1.0
ports:
- containerPort: 8080
resources:
limits:
memory: 128Mi
cpu: 0.5Проверяем факт создания пода
kubectl get podsУдалось!
Основные команды управления пользователями
Если при создании ... указать флаг --embed-certs=true то тогда вместо путей к файлам сертификатов, в файл настройки будут встроено содержание сертификатов в Base64.
| Команда | Доп. параметры |
Описание |
| kubectl get clusterroles.rbac.authorization.k8s.io --all-namespaces | Список пользователей | |
| kubectl config view | Показать текущую конфигурацию (.kube/config) | |
| kubectl config current-context | Показать текущий активный контекст | |
| kubectl config get-contexts | Список всех контекстов | |
| kubectl config use-context cont_name | Переключиться на контекст cont_name | |
| kubectl config set-cluster clast_name | Добавить/изменить кластер
|
|
| kubectl config set-credentials | Добавить/изменить учетные данные пользователя
|
|
| kubectl config set-context cont_name | --cluster=dev-cluster \ --user=dev-user \ --namespace=dev-ns |
Создать/изменить контекст |
| kubectl config delete-context | Удалить контекст | |
| kubectl config delete-cluster | Удалить кластер | |
| kubectl config delete-user user_name | Удалить пользователя | |
| kubectl config rename-context | Переименовать контекст |
Безопасность, общая теория
Запрет передачи ключей SA
Каждому поду по умолчанию передаются ключи сервисный аккаунт. Поэтому при получении доступа к поду можно получить доступ вплоть до всего кластера. Обычно подам не нужно управлять кластером. Поэтому можно запретить передачу ключей.
apiVersion: v1
kind: Pod
metadata:
name: service-account-example-pod
spec:
serviceAccountName: some-service-account
automountServiceAccountToken: false <<==== This line
<Snip>Также можно передавать временные ключи, но это потом.
Контроль целостности ресурсов
- Ограничьте доступ к серверам, на которых запущены компоненты Kubernetes, особенно к компонентам control plane
- Ограничьте доступ к репозиториям, хранящим конфигурационные файлы Kubernetes
- Передача файлов и управление только через SSH
- Проверка контрольной суммы после скачивания
- Ограничьте доступ к регистру образов и связанным хранилищам
Файловая система пода в read-only режим
apiVersion: v1
kind: Pod
metadata:
name: readonly-test
spec:
securityContext:
readOnlyRootFilesystem: true <<==== R/O root filesystem
allowedHostPaths: <<==== Make anything below
- pathPrefix: "/test" <<==== this mount point
readOnly: true <<==== read-only (R/O)
<Snip>Лог действий на кластере и связанной инфраструктуре
Защита данных кластера
Cluster store (обычно etcd) хранит все данные. Необходимо ограничить и контролировать доступ к серверам, на которых работает Cluster store.
DoS
Подвергается API сервер. Должно быть минимум 3 Control plane сервера и 3 worker ноды. Изоляция etcd на сетевом уровне. Ограничения ресурсов для подов и количества подов.
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-quota
namespace: skippy
spec:
hard:
pods: "100"Доп. опция podPidsLimit ограничивает количество процессов одним подом. Также можно ограничить кол-во подов на одной ноде.
По умолчанию etcd устанавливается на сервер с control plane. На production кластере нужно разделять.
Запретить сетевое взаимодействие между подами и внешние взаимодействия (где это не нужно) при помощи сетевых политик Kubernetes.
Защита подов и контейнеров
Запрет запуска процессов от root
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
securityContext: <<==== Applies to all containers in this Pod
runAsUser: 1000 <<==== Non-root user
containers:
- name: demo
image: example.io/simple:1.0
Это запускает все контейнеры от одного непривилегированного пользователя, но позволяет контейнерам использовать общие ресурсы. При запуске нескольких подов, будет аналогично. Поэтому лучше дополнительно настраивать пользователей контейнера:
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
securityContext: <<==== Applies to all containers in this Pod
runAsUser: 1000 <<==== Non-root user
containers:
- name: demo
image: example.io/simple:1.0
securityContext:
runAsUser: 2000 <<==== Overrides the Pod-level settingРутовые права складываются примерно из 30 capabilities. Простой способ - в тестовом окружении ограничить все и по логам добавлять нужные. Естественно финальное тестирование должно быть максимально всеобъемлющим. Пример разрешений:
apiVersion: v1
kind: Pod
metadata:
name: capability-test
spec:
containers:
- name: demo
image: example.io/simple:1.0
securityContext:
capabilities:
add: ["NET_ADMIN", "CHOWN"]
Фильтрация системных вызовов.
Похоже на capabilities, но фильтрует системные вызовы. Способы поиска минимальных разрешений: разрешить все + логгирование, запрет + постепенное разрешение.
Также есть Pod Security Standarts (PSS) и Pod Security Admission (PSA). PSA применяют PSS при старте пода.
Основные команды
| Параметр | Описание |
| kubectl describe clusterrole role_name | Описание роли |
| kubectl get clusterrolebindings | grep role_name | Список пользователей с такой ролью |
| kubectl describe clusterrolebindings role_name | Информация по сопоставлению |
| Аналогично для ролей (clusterrolebindings -> rolebindings) |
Job, cronjob
Job
Выполнения разовой задачи. Если запуск задачи завершается с ошибкой, Job перезапускает поды до успешного выполнения или до истечения таймаутов. Когда задача выполнена, Job считается завершённым и больше никогда в кластере не запускается.
Параметры в spec:
| Параметр | Описание |
| activeDeadlineSeconds | количество секунд, которое отводится всему Job (не для одного пода) на выполнение. |
| backoffLimit | количество попыток. Если указать 2, то Job дважды попробует запустить под и остановится. |
| ttlSecondsAfterFinished | через сколько секунд специальный TimeToLive контроллер должен удалить завершившийся Job вместе с подами и их логами |
После успешного завершения задания манифесты (Job и созданные поды) остаются в кластере навсегда. Все поля Job имеют статус Immutable, и поэтому при создании Job из автоматических сценариев сначала удаляют Job, который остался от предыдущего запуска. Генерация уникальных имен для Job приведет к накоплению ненужных манифестов. Обязательно указание ttlseconds...
При создании бесконечного цикла через activeDeadlineSeconds будет отправлен sigterm, затем через 30 секунд sigkill.
Если указать backoffLimit без restartPolicy, то при ошибке Job будет выполняться бесконечно.
Cronjob
Создание Job по расписанию.
Параметры в spec:
| Параметр | Описание |
| schedule | Расписание в виде строчки в cron-формате. |
| startingDeadlineSeconds | Опциональный. Если по прошествии этого времени job не стартовал, старт отменяется. Желательно вместе с Forbid. |
| concurrencyPolicy |
Одновременное выполнение заданий.
Replace заменяет запущенную нагрузку: старый Job убивается, запускается новый. Не самый лучший вариант, этот вариант осознанно.
|
| successfulJobsHistoryLimit |
Глубина истории хранения удачных job, по умолчанию 3 |
| failedJobsHistoryLimit |
Глубина истории хранения неудачных job, по умолчанию 1 |
CronJob использовать аккуратно. Должны быть независимы и иметь возможность работать параллельно. В качестве альтернативы CronJob можно использовать под, в котором запущен самый обычный crond.
Основные команды
| Команда | Доп. пар. | Описание |
| kubectl get job | список job | |
| --all-namespaces | ||
| kubectl delete job jname | Удалить jname | |
| kubectl get cronjobs.batch | Список cronjob |
Примеры
Job
apiVersion: batch/v1
kind: Job
metadata:
name: hello
spec:
backoffLimit: 2
activeDeadlineSeconds: 60
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: NeverCronjob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
concurrencyPolicy: Allow
jobTemplate:
spec:
backoffLimit: 2
activeDeadlineSeconds: 100
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: Never